Sign language translation (SLT) aims to interpret sign video sequences into text-based natural language sentences.
StanLei52/GEBD
ICCV 2019.
Compared with the non-local block, the proposed recurrent criss-cross attention module requires 11x less GPU memory usage.
Video summarization is a technique to create a short skim of the original video while preserving the main stories/content. This paper tackles the task of semi-supervised video object segmentation, i. e., the separation of an object from the background in a video, given the mask of the first frame.
NeurIPS 2020. subtri/video_inference
verashira/TSPNet ICCV 2021. fperazzi/davis
kmaninis/OSVOS-PyTorch 6 datasets, BehradToghi/ECCV_Youtube_VOS
6 datasets, BehradToghi/ECCV_Youtube_VOS  Papers With Code is a free resource with all data licensed under, YouTube-VOS: Sequence-to-Sequence Video Object Segmentation, Video Object Segmentation with Re-identification, CCNet: Criss-Cross Attention for Semantic Segmentation, Physarum Powered Differentiable Linear Programming Layers and Applications, Rethinking the Evaluation of Video Summaries, TSPNet: Hierarchical Feature Learning via Temporal Semantic Pyramid for Sign Language Translation, Generic Event Boundary Detection: A Benchmark for Event Segmentation, Semantic Video Segmentation : Exploring Inference Efficiency, A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation. 60 papers with code
Papers With Code is a free resource with all data licensed under, YouTube-VOS: Sequence-to-Sequence Video Object Segmentation, Video Object Segmentation with Re-identification, CCNet: Criss-Cross Attention for Semantic Segmentation, Physarum Powered Differentiable Linear Programming Layers and Applications, Rethinking the Evaluation of Video Summaries, TSPNet: Hierarchical Feature Learning via Temporal Semantic Pyramid for Sign Language Translation, Generic Event Boundary Detection: A Benchmark for Event Segmentation, Semantic Video Segmentation : Exploring Inference Efficiency, A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation. 60 papers with code
CVPR 2016.
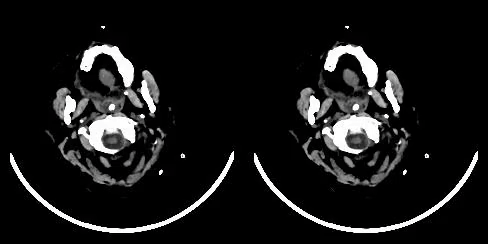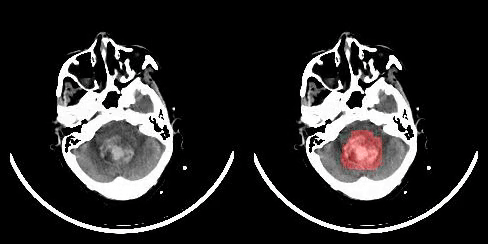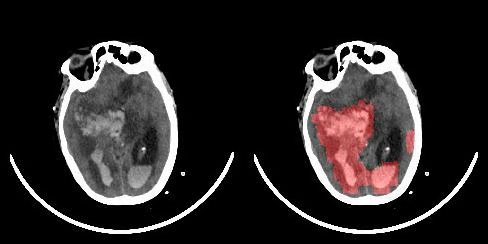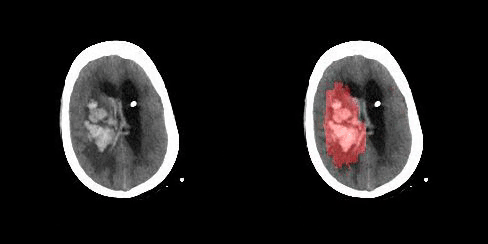 1 benchmarks
1 benchmarks
We explore the efficiency of the CRF inference beyond image level semantic segmentation and perform joint inference in video frames. End-to-end sequential learning to explore spatial-temporal features for video segmentation is largely limited by the scale of available video segmentation datasets, i. e., even the largest video segmentation dataset only contains 90 short video clips. CVPR 2019. HeatherJiaZG/SuperGlue-pytorch 1 Aug 2017.
30 Apr 2020.
mayu-ot/rethinking-evs We describe our development and show the use of our solver in a video segmentation task and meta-learning for few-shot learning.
speedinghzl/CCNet Specifically, our Video Object Segmentation with Re-identification (VS-ReID) model includes a mask propagation module and a ReID module.
lxx1991/VS-ReID
CVPR 2017.
ECCV 2018. This paper presents a novel task together with a new benchmark for detecting generic, taxonomy-free event boundaries that segment a whole video into chunks. The dataset, named DAVIS (Densely Annotated VIdeo Segmentation), consists of fifty high quality, Full HD video sequences, spanning multiple occurrences of common video object segmentation challenges such as occlusions, motion-blur and appearance changes.
4 Sep 2015.
Stay informed on the latest trending ML papers with code, research developments, libraries, methods, and datasets.
StanLei52/GEBD
ICCV 2019.
Compared with the non-local block, the proposed recurrent criss-cross attention module requires 11x less GPU memory usage.
Video summarization is a technique to create a short skim of the original video while preserving the main stories/content. This paper tackles the task of semi-supervised video object segmentation, i. e., the separation of an object from the background in a video, given the mask of the first frame.
NeurIPS 2020. subtri/video_inference
verashira/TSPNet ICCV 2021. fperazzi/davis
kmaninis/OSVOS-PyTorch
6 datasets, BehradToghi/ECCV_Youtube_VOS Papers With Code is a free resource with all data licensed under, YouTube-VOS: Sequence-to-Sequence Video Object Segmentation, Video Object Segmentation with Re-identification, CCNet: Criss-Cross Attention for Semantic Segmentation, Physarum Powered Differentiable Linear Programming Layers and Applications, Rethinking the Evaluation of Video Summaries, TSPNet: Hierarchical Feature Learning via Temporal Semantic Pyramid for Sign Language Translation, Generic Event Boundary Detection: A Benchmark for Event Segmentation, Semantic Video Segmentation : Exploring Inference Efficiency, A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation. 60 papers with code CVPR 2016.
1 benchmarks We explore the efficiency of the CRF inference beyond image level semantic segmentation and perform joint inference in video frames. End-to-end sequential learning to explore spatial-temporal features for video segmentation is largely limited by the scale of available video segmentation datasets, i. e., even the largest video segmentation dataset only contains 90 short video clips. CVPR 2019. HeatherJiaZG/SuperGlue-pytorch 1 Aug 2017.
30 Apr 2020.
mayu-ot/rethinking-evs We describe our development and show the use of our solver in a video segmentation task and meta-learning for few-shot learning.
speedinghzl/CCNet Specifically, our Video Object Segmentation with Re-identification (VS-ReID) model includes a mask propagation module and a ReID module.
lxx1991/VS-ReID
CVPR 2017.
ECCV 2018. This paper presents a novel task together with a new benchmark for detecting generic, taxonomy-free event boundaries that segment a whole video into chunks. The dataset, named DAVIS (Densely Annotated VIdeo Segmentation), consists of fifty high quality, Full HD video sequences, spanning multiple occurrences of common video object segmentation challenges such as occlusions, motion-blur and appearance changes.
4 Sep 2015.
Stay informed on the latest trending ML papers with code, research developments, libraries, methods, and datasets.