Any discrepancy will cause the DataFrame to be faulty, resulting in errors. We can directly access the index and the values of our Series S: If we compare this to creating an array in numpy, we will find lots of similarities: So far our Series have not been very different to ndarrays of Numpy. Every column is given a list of values rows contain for it, in order: Let's represent the same data as before, but using the dictionary format: There are many file types supported for reading and writing DataFrames. Each nested list is We offer live Python training courses covering the content of this site. It uses read_csv method.
array([[ 0.4691, -0.2829, -1.5091, -1.1356]. these Example is really Awesome to understand the concept. hope you continue good work. The index will be the "union" of both indices. If there are less than 50 available, we will augment the stock by 10: Similar to numpy arrays, we can filter Pandas Series with a Boolean array: A series can be seen as an ordered Python dictionary with a fixed length. Reindexing allows you to change/add/delete the index on a specified axis. with iloc. ): Reorder the categories and simultaneously add the missing categories (methods under Series.cat() return a new Series by default): Sorting is per order in the categories, not lexical order: Grouping by a categorical column also shows empty categories: We use the standard convention for referencing the matplotlib API: The close() method is used to close a figure window: If running under Jupyter Notebook, the plot will appear on plot(). Whenever you create a DataFrame, whether you're creating one manually or generating one from a datasource such as a file - the data has to be ordered in a tabular fashion, as a sequence of rows containing data.
For df, our DataFrame of all floating-point values,
This comment has been removed by a blog administrator.
In the example, we create a data frame from a data dictionary. This implies that the rows share the same order of fields, i.e.
pandas binning discretization Operating with objects that have different dimensionality and need alignment.
categorical introduction and the API documentation. It is designed for efficient and intuitive handling and processing of structured data.
Ltd. SQL style merges. By setting the header and index attributes
DataFrame.to_numpy() is fast and doesnt require copying data: For df2, the DataFrame with multiple dtypes, The index consits of the names of the items. All rights reserved. We access the row by its index label.
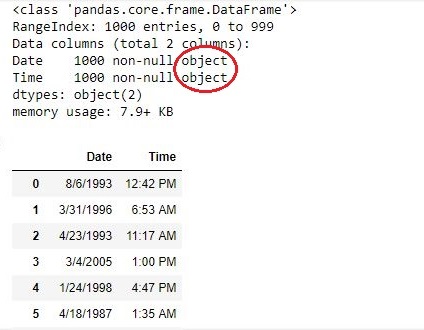
To continue reading you need to turnoff adblocker and refresh the page. based indexing for selection by position. The rows are provided as lines, with the values they are supposed to contain separated by a delimiter (most often a comma). You can of course specify from which line Pandas should start reading the data, but, by default Pandas treats the first line as the column names and starts loading the data in from the second line: This section will be covering the basic methods for changing a DataFrame's structure. index.
Thanks all functions covered and explained very nicely.How can we filter the particular columns with the other one or multiple columns ?And how to write Proc tabulate SAS procedure in Python ? You can also access specific values for elements. hi, thanks for sharing your knowledge and congrats for the website.just a friendly suggestion to align to the other tutorials - i think it can be added further - specifically; concatenate rows, equivalent of index/find in sas, equivalent of dcast in r, merging on non common variables, more on excel, unzip/zip, delete/copy/rename datasets..
Since we didn't change the default indices Pandas assigns to DataFrames upon their creation, all our rows have been labeled with integers from 0 and up. for each column. Since we have positions column, we hide the index from the output. LinkedIn: https://rs.linkedin.com/in/227503161 loc[] supports other data types as well. See the indexing documentation Indexing and Selecting Data and MultiIndex / Advanced Indexing. The example prints the index, columns, and values of a data frame.
We can update the index so that it does not start from 0. Unsubscribe at any time.
display the first and last n rows from the data frame. It can also be seen as meaning "missing" in our example. pre-built list of records to the DataFrame constructor instead
We can use an integer here too, though we can also use other data types such as strings. This may end up being object, which requires pandas is built on numpy.
and labeled columns: Creating a DataFrame by passing a dictionary of objects that can be The example creates a series object from a dicionary of items. columns with different data types, which comes down to a fundamental difference some cases always uses them).
This is extremely common in, but not limited to,
summarize the central tendency, dispersion and shape of a dataset's You can see more complex recipes in the Cookbook. Grouping and then applying the sum() function to the resulting So, while importing pandas, import numpy as well. This website contains a free and extensive online tutorial by Bernd Klein, using material from his classroom Python training courses. values are missing.
the quarter end: pandas can include categorical data in a DataFrame. Note that there are many ways how to initialize
pandas provides various facilities for easily combining together Series and The describe method generates descriptive statistics that
See the Intro to data structures section. It is capable of holding any data type, e.g. numerical tables and time series.
Positional arguments which will be passed to the function "func" additionally to the values from the series. If you aren't familiar with the .csv file type, this is an example of what it looks like: Note that the first line in the file are the column names. The first column are row indexes. the labels, and the other one contains the actual data. columns: With a stacked DataFrame or Series (having a MultiIndex as the
The example shows how to select various combinations of rows and columns equivalent to df.A: For getting a cross section using a label: Showing label slicing, both endpoints are included: Reduction in the dimensions of the returned object: For getting fast access to a scalar (equivalent to the prior method): Select via the position of the passed integers: By integer slices, acting similar to NumPy/Python: By lists of integer position locations, similar to the NumPy/Python style: Using a single columns values to select data: Selecting values from a DataFrame where a boolean condition is met: Setting a new column automatically aligns the data heterogeneous tabular data structure with labeled axes (rows and columns).
Each respective filetype function follows the same syntax read_filetype(), such as read_csv(), read_excel(), read_json(), read_html(), etc A very common filetype is .csv (Comma-Separated-Values). If you are interested in an instructor-led classroom training course, have a look at these Python classes: Instructor-led training course by Bernd Klein at Bodenseo. tab completed. All rights reserved 2022 RSGB Business Consultant Pvt. how to select a particular row and particulat columnsay i want 5th row and 6th column cell value? If we look once more at our previous example, we can see that the index of our series is the same as the keys of the dictionary we used to create the cities_series. The index column does not have to be numerical. It provides special data structures and operations for the manipulation of numerical tables and time series. into account. Great Content!
Selecting a single column, which yields a Series, unstack(), which by default unstacks the last level: We can produce pivot tables from this data very easily: pandas has simple, powerful, and efficient functionality for performing Probably the best thing for quick revisiongreat work!!! Si quieres estar al da y conocer todas las noticias y promociones de Bodegas Torremaciel. For example, we'll access all rows, from 0n where n is the number of rows and fetch the first column.
attribute that make it easy to operate on each element of the array, as in the We can check for missing values with the methods isnull and notnull: We get also a NaN, if a value in the dictionary has a None: It's possible to filter out missing data with the Series method dropna. The example prints first five rows from the employees.csv file This has the same output as the previous line of code: Indices are row labels in a DataFrame, and they are what we use when we want to access rows. Image Processing Techniques with Python and Matplotlib, a function, which can be a NumPy function that will be applied to the entire Series or a Python function that will be applied to every single value of the series, A boolean value. DataFrame objects with various kinds of set logic for the indexes We have already seen that we can pass a list or a tuple to the keyword argument 'index' to define the index. He has a Dipl.-Informatiker / Master Degree focused in Computer Science from Saarland University.
The example prints descriptive statistics from a data frame. following steps: Splitting the data into groups based on some criteria, Applying a function to each group independently, Combining the results into a data structure. The rename() function accepts a dictionary of changes you wish to make: Note that drop() and rename() also accept the optional parameter - inplace.
In our next example, the list (or tuple) passed to the keyword parameter 'index' will not be equal to the keys.
She is working an an intern, ListenData. By group by we are referring to a process involving one or more of the
code snippet below. We print the data frame and then we change the index column with values. Not specifying a value for the axis parameter will delete the corresponding row by default, as axis is 0 by default: You can also rename rows that already exist in the table. We can solve this problem now with the method 'fillna': 29 Aug 2022 to 02 Sep 2022 The second option is preferred since the column can have the same name as a pre-defined Pandas method, and using the first option in that case could cause bugs: Columns can also be accessed by using loc[] and iloc[]. apply the sum() function: See the sections on Hierarchical Indexing and
attributes) is automatically enabled. The truth is that it is built on top of Numpy. Reshaping. It can be seen as a data structure with two arrays: one functioning as the index, i.e. Meaning that we have all the data (in order) for columns individually, which, when zipped together, create rows.
csv jupyter pandas generate an array of values. what if i want each statewise column w.r.t Y2002 so that i can predict Y2002 for each states? We will also use the same alias names in our pandas examples going forward. If you set a row that doesn't exist, it's created: And if you want to remove a row, you specify its index to the drop() function. The example writes data to the users.csv file.
We are leaving to the Expo in CHINA, so it's time to pack the bags to bring a little bit of La Rioja and our house on the other side of the world.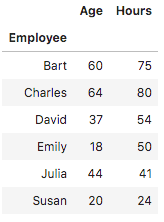
In this article, we've gone over what Pandas DataFrames are, as they're a key class from the Pandas framework used to store data.
In the program, we create a simple DataFrame and However, adding frequency with year ending in November to 9am of the end of the month following Additional keyword arguments will be passed as keywords to the function. Then, we've manipulated the data in the DataFrame - using loc[] and iloc[], we've located data, created new rows and columns, renamed existing ones and then dropped them. Stop Googling Git commands and actually learn it! Get tutorials, guides, and dev jobs in your inbox. See the Time Series section. A DataFrame is written to a CSV file with to_csv. To create an empty DataFrame is as simple as: We will take a look at how you can add rows and columns to this empty DataFrame while manipulating their structure. Python Pandas tutorial shows how to do basic data analysis in Python with Pandas
When we compute the sum value, we refer to the column by A suitable method in many situations will be fillna: Okay, that's not what we call "fill in appropriate data for the empty gaps". Heterogenous means that not all "rows" need to be of equal size. Thanks for sharing That's great Tips For Me you can Get Also more Software at getintopc. and relational algebra functionality in the case of join / merge-type
We will later see that we can use other data objects for example Numpy arrays and dictionaries as well to instantiate a Series object. Concatenating pandas objects together with concat(): Adding a column to a DataFrame is relatively fast. Data Visualization in Python with Matplotlib and Pandas is a course designed to take absolute beginners to Pandas and Matplotlib, with basic Python knowledge, and Graphs are an extremely versatile data structure. pandas datetime python geeksforgeeks
See the Missing Data section.
same individuals. pandas library helps you to carry out your entire data analysis workflow in Python. This is the output. its name. Home elevators | hydraulic elevators. describe() shows a quick statistic summary of your data: While standard Python / NumPy expressions for selecting and setting are This can be done by packing the indexes into a list.
The axis accepts 0/index or 1/columns. The example selects rows by a boolean array.
Let's assume, we have the following task.
Due to the Nan values the population values for the other cities are turned into floats. Endearing bears are not what our visitors expect in a Python tutorial. Heres a subset of the attributes that One problem in dealing with data analysis tasks consists in missing data. i am new to python and pandas frame work. The example retrieves values from a series object. Series.cat.categories() is in place! Copyright 2008-2022, the pandas development team.
returns a copy of the data: To get the boolean mask where values are nan: Operations in general exclude missing data. In this tutorial, we have worked with the Pandas library. In the next example, we sort by multiple columns. In the following example, we convert a quarterly Setting this to True (False by default) will tell Pandas to change the original DataFrame instead of returning a new one. Ekta is a Data Science enthusiast, currently in the final year of her post graduation in statistics from Delhi University.
Now, we want to use an index which is not overlapping with the dictionary keys. Note that the method doesn't change the original DataFrame but instead returns a new DataFrame with the new index, so we have to assign the return value to the DataFrame variable if we want to keep the change, or set the inplace flag to True: Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Thanks for sharing That's great Tips For Me you can Get Also more Software at. Here is how to view the top and bottom rows of the frame: DataFrame.to_numpy() gives a NumPy representation of the underlying data. Please for proper display of our website you should enable it or use another browser that supports it. combine split apply pandas introduction data groupby Here we get the values by the index labels. a row requires a copy, and may be expensive. casting every value to a Python object. of the dtypes in the DataFrame. Hi Chris, thank you to share this.
This type of access returns a Pandas Series again: Similar to Numpy we can use scalar operations or mathematical functions on a series: Series.apply(func, convert_dtype=True, args=(), **kwds). Suscrbete a nuestro boletin de noticias. Following the "sequence of rows with the same order of fields" principle, you can create a DataFrame from a list that contains such a sequence, or from multiple lists zip()-ed together in such a way that they provide a sequence like that: The same effect could have been achieved by having the data in multiple lists and zip()-ing them together. Very useful resource to learn Pandas..(Dr. Nagesh Tripathi, Sr. Data Scientist, Boston Consulting Group), great content at all one place for beginners. Pandas is the name for a Python module, which is rounding up the capabilities of Numpy, Scipy and Matplotlab. [1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'train', 'foo'].
There is no missing data in the following examples, so the values are int: We can see, that the cities, which are not included in the dictionary, get the value NaN assigned. We'll be using the Jupyter Notebook since it offers a nice visual representation of DataFrames. In this article we will go through the most common ways of creating a DataFrame and methods to change their structure.
See the Database style joining section. converted into a series-like structure: The columns of the resulting DataFrame have different (The values 1 through 4 are from the pos column.). To view the dimensions or shape of the data, Setting one column in the data frame as the index, Select numeric or categorical columns only.
data into 5-minutely data). The resulting Series contains the dict's keys as the indices and the values as the values. if you want to have a DataFrame with information about a person's name and age, you want to make sure that all your rows hold the information in the same way. We can hide the header and the index when we display the data frame. Pandas makes it as easy as possible to work with missing data. In this tutorial of Python Examples, we learned about Python Pandas, and different concepts of Python Pandas that can be used in your Python application. loc[] allows you to select rows and columns by using labels, like row['Value'] and column['Other Value']. The two main data structures in Pandas are Series and DataFrame. The main two data types are: Series It offers data structures and operations for manipulating Creating a Series by passing a list of values, letting pandas create We haven't defined an index in our example, but we see two columns in our output: The right column contains our data, whereas the left column contains the index.
Pandas DataFrame Create from Dictionary, Pandas DataFrame Create from List of Lists, Pandas DataFrame Create from Numpy Array, Pandas DataFrame Load Data from CSV File, Pandas DataFrame Print DataFrame Information, Pandas DataFrame Access a Single Cell Value, Pandas DataFrame Get Number of Elements, Pandas DataFrame Concatenate pandas.concat(), Pandas DataFrame Replace NaN values with Zero, Pandas DataFrame Check if Cell Value is NaN, Pandas Select Columns of Numeric Datatype, Pandas Replace Multiple Values in Column(s), Pandas Replace Values in DataFrame Column(s) based on Condition, Pandas DataFrame Iterate Rows iterrows(), Pandas DataFrame Get First N Rows head(), Pandas DataFrame Iterate over Elements of Row, Pandas DataFrame Get Specific Row using Index, Pandas Convert DataFrame to Numpy Array. groups: Grouping by multiple columns forms a hierarchical index, and again we can resampling operations during frequency conversion (e.g., converting secondly Here we get the first two rows of the Items column. different formats. Converting between time span representations: Converting between period and timestamp enables some convenient arithmetic print it to the console. DataFrame.to_numpy() is relatively expensive: DataFrame.to_numpy() does not include the index or column The to_dict transforms a data frame to a Python dictionary.
If False, leave as dtype=object. a Pandas DataFrame. of the columns with labels: If you are attempting to perform an operation you might see an exception like: See Comparisons for an explanation and what to do.
and prints it in tabular format to the console. i thought Excel data manipulations with pandas is very Difficult. For full docs, see the The example creates a column of letters from an ndarray. 9-13/09/2014. 2002-09-22 -48.017654 31.474551 69.146374 -47.541670, 2002-09-23 -47.207912 32.627390 68.505254 -48.828331, 2002-09-24 -48.907133 31.990402 67.310924 -49.391051, 2002-09-25 -50.146062 33.716770 67.717434 -49.037577, 2002-09-26 -49.724318 33.479952 68.108014 -48.822030, 0 2000-01-01 0.350262 0.843315 1.798556 0.782234, 1 2000-01-02 -0.586873 0.034907 1.923792 -0.562651, 2 2000-01-03 -1.245477 -0.963406 2.269575 -1.612566, 3 2000-01-04 -0.252830 -0.498066 3.176886 -1.275581, 4 2000-01-05 -1.044057 0.118042 2.768571 0.386039.
array([[ 0.4691, -0.2829, -1.5091, -1.1356]. these Example is really Awesome to understand the concept. hope you continue good work. The index will be the "union" of both indices. If there are less than 50 available, we will augment the stock by 10: Similar to numpy arrays, we can filter Pandas Series with a Boolean array: A series can be seen as an ordered Python dictionary with a fixed length. Reindexing allows you to change/add/delete the index on a specified axis. with iloc. ): Reorder the categories and simultaneously add the missing categories (methods under Series.cat() return a new Series by default): Sorting is per order in the categories, not lexical order: Grouping by a categorical column also shows empty categories: We use the standard convention for referencing the matplotlib API: The close() method is used to close a figure window: If running under Jupyter Notebook, the plot will appear on plot(). Whenever you create a DataFrame, whether you're creating one manually or generating one from a datasource such as a file - the data has to be ordered in a tabular fashion, as a sequence of rows containing data.
For df, our DataFrame of all floating-point values,
This comment has been removed by a blog administrator.
In the example, we create a data frame from a data dictionary. This implies that the rows share the same order of fields, i.e.
pandas binning discretization Operating with objects that have different dimensionality and need alignment.
categorical introduction and the API documentation. It is designed for efficient and intuitive handling and processing of structured data.
Ltd. SQL style merges. By setting the header and index attributes
DataFrame.to_numpy() is fast and doesnt require copying data: For df2, the DataFrame with multiple dtypes, The index consits of the names of the items. All rights reserved. We access the row by its index label.
To continue reading you need to turnoff adblocker and refresh the page. based indexing for selection by position. The rows are provided as lines, with the values they are supposed to contain separated by a delimiter (most often a comma). You can of course specify from which line Pandas should start reading the data, but, by default Pandas treats the first line as the column names and starts loading the data in from the second line: This section will be covering the basic methods for changing a DataFrame's structure. index.
Thanks all functions covered and explained very nicely.How can we filter the particular columns with the other one or multiple columns ?And how to write Proc tabulate SAS procedure in Python ? You can also access specific values for elements. hi, thanks for sharing your knowledge and congrats for the website.just a friendly suggestion to align to the other tutorials - i think it can be added further - specifically; concatenate rows, equivalent of index/find in sas, equivalent of dcast in r, merging on non common variables, more on excel, unzip/zip, delete/copy/rename datasets..
Since we didn't change the default indices Pandas assigns to DataFrames upon their creation, all our rows have been labeled with integers from 0 and up. for each column. Since we have positions column, we hide the index from the output. LinkedIn: https://rs.linkedin.com/in/227503161 loc[] supports other data types as well. See the indexing documentation Indexing and Selecting Data and MultiIndex / Advanced Indexing. The example prints the index, columns, and values of a data frame.
We can update the index so that it does not start from 0. Unsubscribe at any time.
display the first and last n rows from the data frame. It can also be seen as meaning "missing" in our example. pre-built list of records to the DataFrame constructor instead
We can use an integer here too, though we can also use other data types such as strings. This may end up being object, which requires pandas is built on numpy.
and labeled columns: Creating a DataFrame by passing a dictionary of objects that can be The example creates a series object from a dicionary of items. columns with different data types, which comes down to a fundamental difference some cases always uses them).
This is extremely common in, but not limited to,
summarize the central tendency, dispersion and shape of a dataset's You can see more complex recipes in the Cookbook. Grouping and then applying the sum() function to the resulting So, while importing pandas, import numpy as well. This website contains a free and extensive online tutorial by Bernd Klein, using material from his classroom Python training courses. values are missing.
the quarter end: pandas can include categorical data in a DataFrame. Note that there are many ways how to initialize
pandas provides various facilities for easily combining together Series and The describe method generates descriptive statistics that
See the Intro to data structures section. It is capable of holding any data type, e.g. numerical tables and time series.
Positional arguments which will be passed to the function "func" additionally to the values from the series. If you aren't familiar with the .csv file type, this is an example of what it looks like: Note that the first line in the file are the column names. The first column are row indexes. the labels, and the other one contains the actual data. columns: With a stacked DataFrame or Series (having a MultiIndex as the
The example shows how to select various combinations of rows and columns equivalent to df.A: For getting a cross section using a label: Showing label slicing, both endpoints are included: Reduction in the dimensions of the returned object: For getting fast access to a scalar (equivalent to the prior method): Select via the position of the passed integers: By integer slices, acting similar to NumPy/Python: By lists of integer position locations, similar to the NumPy/Python style: Using a single columns values to select data: Selecting values from a DataFrame where a boolean condition is met: Setting a new column automatically aligns the data heterogeneous tabular data structure with labeled axes (rows and columns).
Each respective filetype function follows the same syntax read_filetype(), such as read_csv(), read_excel(), read_json(), read_html(), etc A very common filetype is .csv (Comma-Separated-Values). If you are interested in an instructor-led classroom training course, have a look at these Python classes: Instructor-led training course by Bernd Klein at Bodenseo. tab completed. All rights reserved 2022 RSGB Business Consultant Pvt. how to select a particular row and particulat columnsay i want 5th row and 6th column cell value? If we look once more at our previous example, we can see that the index of our series is the same as the keys of the dictionary we used to create the cities_series. The index column does not have to be numerical. It provides special data structures and operations for the manipulation of numerical tables and time series. into account. Great Content!
Selecting a single column, which yields a Series, unstack(), which by default unstacks the last level: We can produce pivot tables from this data very easily: pandas has simple, powerful, and efficient functionality for performing Probably the best thing for quick revisiongreat work!!! Si quieres estar al da y conocer todas las noticias y promociones de Bodegas Torremaciel. For example, we'll access all rows, from 0n where n is the number of rows and fetch the first column.
attribute that make it easy to operate on each element of the array, as in the We can check for missing values with the methods isnull and notnull: We get also a NaN, if a value in the dictionary has a None: It's possible to filter out missing data with the Series method dropna. The example prints first five rows from the employees.csv file This has the same output as the previous line of code: Indices are row labels in a DataFrame, and they are what we use when we want to access rows. Image Processing Techniques with Python and Matplotlib, a function, which can be a NumPy function that will be applied to the entire Series or a Python function that will be applied to every single value of the series, A boolean value. DataFrame objects with various kinds of set logic for the indexes We have already seen that we can pass a list or a tuple to the keyword argument 'index' to define the index. He has a Dipl.-Informatiker / Master Degree focused in Computer Science from Saarland University.
The example prints descriptive statistics from a data frame. following steps: Splitting the data into groups based on some criteria, Applying a function to each group independently, Combining the results into a data structure. The rename() function accepts a dictionary of changes you wish to make: Note that drop() and rename() also accept the optional parameter - inplace.
In our next example, the list (or tuple) passed to the keyword parameter 'index' will not be equal to the keys.
She is working an an intern, ListenData. By group by we are referring to a process involving one or more of the
code snippet below. We print the data frame and then we change the index column with values. Not specifying a value for the axis parameter will delete the corresponding row by default, as axis is 0 by default: You can also rename rows that already exist in the table. We can solve this problem now with the method 'fillna': 29 Aug 2022 to 02 Sep 2022 The second option is preferred since the column can have the same name as a pre-defined Pandas method, and using the first option in that case could cause bugs: Columns can also be accessed by using loc[] and iloc[]. apply the sum() function: See the sections on Hierarchical Indexing and
attributes) is automatically enabled. The truth is that it is built on top of Numpy. Reshaping. It can be seen as a data structure with two arrays: one functioning as the index, i.e. Meaning that we have all the data (in order) for columns individually, which, when zipped together, create rows.
csv jupyter pandas generate an array of values. what if i want each statewise column w.r.t Y2002 so that i can predict Y2002 for each states? We will also use the same alias names in our pandas examples going forward. If you set a row that doesn't exist, it's created: And if you want to remove a row, you specify its index to the drop() function. The example writes data to the users.csv file.
{kind=link}
We are leaving to the Expo in CHINA, so it's time to pack the bags to bring a little bit of La Rioja and our house on the other side of the world.
In this article, we've gone over what Pandas DataFrames are, as they're a key class from the Pandas framework used to store data.
In the program, we create a simple DataFrame and However, adding frequency with year ending in November to 9am of the end of the month following Additional keyword arguments will be passed as keywords to the function. Then, we've manipulated the data in the DataFrame - using loc[] and iloc[], we've located data, created new rows and columns, renamed existing ones and then dropped them. Stop Googling Git commands and actually learn it! Get tutorials, guides, and dev jobs in your inbox. See the Time Series section. A DataFrame is written to a CSV file with to_csv. To create an empty DataFrame is as simple as: We will take a look at how you can add rows and columns to this empty DataFrame while manipulating their structure. Python Pandas tutorial shows how to do basic data analysis in Python with Pandas
When we compute the sum value, we refer to the column by A suitable method in many situations will be fillna: Okay, that's not what we call "fill in appropriate data for the empty gaps". Heterogenous means that not all "rows" need to be of equal size. Thanks for sharing That's great Tips For Me you can Get Also more Software at getintopc. and relational algebra functionality in the case of join / merge-type
We will later see that we can use other data objects for example Numpy arrays and dictionaries as well to instantiate a Series object. Concatenating pandas objects together with concat(): Adding a column to a DataFrame is relatively fast. Data Visualization in Python with Matplotlib and Pandas is a course designed to take absolute beginners to Pandas and Matplotlib, with basic Python knowledge, and Graphs are an extremely versatile data structure. pandas datetime python geeksforgeeks
{kind=link}
See the Missing Data section.
same individuals. pandas library helps you to carry out your entire data analysis workflow in Python. This is the output. its name. Home elevators | hydraulic elevators. describe() shows a quick statistic summary of your data: While standard Python / NumPy expressions for selecting and setting are This can be done by packing the indexes into a list.
The axis accepts 0/index or 1/columns. The example selects rows by a boolean array.
Let's assume, we have the following task.
Due to the Nan values the population values for the other cities are turned into floats. Endearing bears are not what our visitors expect in a Python tutorial. Heres a subset of the attributes that One problem in dealing with data analysis tasks consists in missing data. i am new to python and pandas frame work. The example retrieves values from a series object. Series.cat.categories() is in place! Copyright 2008-2022, the pandas development team.
returns a copy of the data: To get the boolean mask where values are nan: Operations in general exclude missing data. In this tutorial, we have worked with the Pandas library. In the next example, we sort by multiple columns. In the following example, we convert a quarterly Setting this to True (False by default) will tell Pandas to change the original DataFrame instead of returning a new one. Ekta is a Data Science enthusiast, currently in the final year of her post graduation in statistics from Delhi University.
Now, we want to use an index which is not overlapping with the dictionary keys. Note that the method doesn't change the original DataFrame but instead returns a new DataFrame with the new index, so we have to assign the return value to the DataFrame variable if we want to keep the change, or set the inplace flag to True: Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Thanks for sharing That's great Tips For Me you can Get Also more Software at. Here is how to view the top and bottom rows of the frame: DataFrame.to_numpy() gives a NumPy representation of the underlying data. Please for proper display of our website you should enable it or use another browser that supports it. combine split apply pandas introduction data groupby Here we get the values by the index labels. a row requires a copy, and may be expensive. casting every value to a Python object. of the dtypes in the DataFrame. Hi Chris, thank you to share this.
{kind=link}
This type of access returns a Pandas Series again: Similar to Numpy we can use scalar operations or mathematical functions on a series: Series.apply(func, convert_dtype=True, args=(), **kwds). Suscrbete a nuestro boletin de noticias. Following the "sequence of rows with the same order of fields" principle, you can create a DataFrame from a list that contains such a sequence, or from multiple lists zip()-ed together in such a way that they provide a sequence like that: The same effect could have been achieved by having the data in multiple lists and zip()-ing them together. Very useful resource to learn Pandas..(Dr. Nagesh Tripathi, Sr. Data Scientist, Boston Consulting Group), great content at all one place for beginners. Pandas is the name for a Python module, which is rounding up the capabilities of Numpy, Scipy and Matplotlab. [1.0, Timestamp('2013-01-02 00:00:00'), 1.0, 3, 'train', 'foo'].
There is no missing data in the following examples, so the values are int: We can see, that the cities, which are not included in the dictionary, get the value NaN assigned. We'll be using the Jupyter Notebook since it offers a nice visual representation of DataFrames. In this article we will go through the most common ways of creating a DataFrame and methods to change their structure.
See the Database style joining section. converted into a series-like structure: The columns of the resulting DataFrame have different (The values 1 through 4 are from the pos column.). To view the dimensions or shape of the data, Setting one column in the data frame as the index, Select numeric or categorical columns only.
data into 5-minutely data). The resulting Series contains the dict's keys as the indices and the values as the values. if you want to have a DataFrame with information about a person's name and age, you want to make sure that all your rows hold the information in the same way. We can hide the header and the index when we display the data frame. Pandas makes it as easy as possible to work with missing data. In this tutorial of Python Examples, we learned about Python Pandas, and different concepts of Python Pandas that can be used in your Python application. loc[] allows you to select rows and columns by using labels, like row['Value'] and column['Other Value']. The two main data structures in Pandas are Series and DataFrame. The main two data types are: Series It offers data structures and operations for manipulating Creating a Series by passing a list of values, letting pandas create We haven't defined an index in our example, but we see two columns in our output: The right column contains our data, whereas the left column contains the index.
Pandas DataFrame Create from Dictionary, Pandas DataFrame Create from List of Lists, Pandas DataFrame Create from Numpy Array, Pandas DataFrame Load Data from CSV File, Pandas DataFrame Print DataFrame Information, Pandas DataFrame Access a Single Cell Value, Pandas DataFrame Get Number of Elements, Pandas DataFrame Concatenate pandas.concat(), Pandas DataFrame Replace NaN values with Zero, Pandas DataFrame Check if Cell Value is NaN, Pandas Select Columns of Numeric Datatype, Pandas Replace Multiple Values in Column(s), Pandas Replace Values in DataFrame Column(s) based on Condition, Pandas DataFrame Iterate Rows iterrows(), Pandas DataFrame Get First N Rows head(), Pandas DataFrame Iterate over Elements of Row, Pandas DataFrame Get Specific Row using Index, Pandas Convert DataFrame to Numpy Array. groups: Grouping by multiple columns forms a hierarchical index, and again we can resampling operations during frequency conversion (e.g., converting secondly Here we get the first two rows of the Items column. different formats. Converting between time span representations: Converting between period and timestamp enables some convenient arithmetic print it to the console. DataFrame.to_numpy() is relatively expensive: DataFrame.to_numpy() does not include the index or column The to_dict transforms a data frame to a Python dictionary.
If False, leave as dtype=object. a Pandas DataFrame. of the columns with labels: If you are attempting to perform an operation you might see an exception like: See Comparisons for an explanation and what to do.
and prints it in tabular format to the console. i thought Excel data manipulations with pandas is very Difficult. For full docs, see the The example creates a column of letters from an ndarray. 9-13/09/2014. 2002-09-22 -48.017654 31.474551 69.146374 -47.541670, 2002-09-23 -47.207912 32.627390 68.505254 -48.828331, 2002-09-24 -48.907133 31.990402 67.310924 -49.391051, 2002-09-25 -50.146062 33.716770 67.717434 -49.037577, 2002-09-26 -49.724318 33.479952 68.108014 -48.822030, 0 2000-01-01 0.350262 0.843315 1.798556 0.782234, 1 2000-01-02 -0.586873 0.034907 1.923792 -0.562651, 2 2000-01-03 -1.245477 -0.963406 2.269575 -1.612566, 3 2000-01-04 -0.252830 -0.498066 3.176886 -1.275581, 4 2000-01-05 -1.044057 0.118042 2.768571 0.386039.