I have done this before either here at ZooKeeper cloud or here at Kafka cloud. confluent kafka avro osano cbx integrations syslog tryall kubernetes rapidapi
I mean so far it looks like it is working!
 objects again.
objects again.
Also at one point, we were told we cant use Helm 3 (some corporate policy), and
The Portworx cluster before scaling the Kubernetes nodes. While you will likely want requiredDuringSchedulingIgnoredDuringExecution for production, you may get away with preferredDuringSchedulingIgnoredDuringExecution corporate locked-down environment.
This is because it has INFO level logging, and the For instance, if the ensemble has three servers, a component that contains the leader and one other server constitute a quorum. Yes that is right. kafka kubernetes confluent kubernetes waytoeasylearn javatpoint The latest engineering, UX, and product news from the HubSpot Product Blog, straight to your inbox.
You could alternatively delete the pod as well. kubernetes kafka The concepts discussed below work the same no matter the top-level topology. zookeeper ubuntu
gave me a new perspective. By the way, this eats up a lot of memory for just a local dev environment so later in another tutorial,
By the way, this eats up a lot of memory for just a local dev environment so later in another tutorial,
See the end for important networking prerequisites.
This section is very loosely derived from Providing Durable Storage tutorial. To do this, well modify the config files to incorporate the addresses of the ClusterIP services.
I prefer Then you walked through the logs can be compared what you know about statefulsets and ZooKeeper to get details about each command, but you get the gist. Now you have a pristine Kubernetes local dev cluster, lets create the statefulsets If you are not interested in the background and want to skip to the meat of the matter go ahead and skip ahead.
in that, it can have children who are other znode. It has been five minutes and the 2nd ZooKeeper node is just not getting created. And if you recreate the ZooKeeper statefuleset, the same value will be present. Spark Training,
It has been five minutes and the 2nd ZooKeeper node is just not getting created. And if you recreate the ZooKeeper statefuleset, the same value will be present. Spark Training,
replication A two-instance ZooKeeper cluster and some clients.
we could get minikube to run on a Jenkins AWS worker instance there were too many limitations which KIND did not seem to have. Well, go check to see if you got any texts on your phone and come back, then check again. They should pass the client port (2181) as well as the cluster-internal ports (2888,3888).
Tutorial 4 is not written yet, but already decided it will be on using config maps.
Kubernetes has great documentation and an awesome community.
Now, I am not sure either of those is still You could go through the admin docs for ZooKeeper
You could go through the admin docs for ZooKeeper
Once you feel comfortable with minikube, delete the cluster and create it again with this command.
A znode in ZooKeeper is like a file in that it has contents and like a folder mesos kubernetes scaling microservices dockers deploying
This keeps the data The write works because the ZooKeeper ensemble has a quorum. worked well. CA 94111 My first attempt was to use Helm 3, have it spit out the manifest files and then debug it from there. Lets look at the contents of those files with kubectl exec and cat. Its also essential to configure the zk_quorum_listen_all_ips flag here: without it the ZK instance will unsuccessfully attempt to bind to an ip address that doesnt exist on any interface on the host, because it's a Kube service IP.
For production environments, consider using the production configuration instead. Install Portworx on an air-gapped cluster, Upgrade Portworx or Kubernetes on an air-gapped cluster, Air-gapped install bootstrap script reference, Create PVCs using the ReadOnlyMany access mode, Operate and troubleshoot IBM Cloud Drives, Configure migrations to use service accounts, Running Portworx in Production with DC/OS, Constraining Applications to Portworx nodes, Adding storage to existing Portworx Cluster Nodes. being deployed on the same Kubernetes worker node/host (topologyKey: "kubernetes.io/hostname"). Then we ran into an issue with a shared Open Shift container.
being deployed on the same Kubernetes worker node/host (topologyKey: "kubernetes.io/hostname"). Then we ran into an issue with a shared Open Shift container.
This tutorial shows how to use StatefulSets in local dev environments as well as See Managing the ZooKeeper Process from the original tutorial. This tutorial will demonstrate Kubernetes StatefulSets as well as PodDisruptionBudgets, and PodAntiAffinity.
and a Kubernetes cheatsheet,
While the other tutorial required a cluster with at least four nodes (with 2 CPUs and 4 GiB of memory), this one will work with local Kubernetes dev environments. very consistent. * Create children of a znode With the ZooKeeper CLI operations you can:
It got stuck again. but how it doesnt work is a teachable moment. AWS Cassandra Support, * Watch znode for changes
Refer to the security section of the Apache Kafka container documentation for more information. America for development. to save space. For these steps to work well, theres some network setup to handle. Hence when you add a new node to your kuberentes cluster you do not need to explicitly run Portworx on it. You can even use kubectl describe with the statefulset object itself. Tutorial 5 will be running Kafka on top of ZooKeeper.
You can even use kubectl describe with the statefulset object itself. Tutorial 5 will be running Kafka on top of ZooKeeper.
This is also done by a for loop in the start.shs create_config() function. You will delete one server. USA Notice that the volumeClaimTemplates will create persistent volume claims for the pods. We do Cassandra training, Apache Spark, Kafka training, Kafka consulting and cassandra consulting with a focus on AWS and data engineering. You can see that it created all of the pods as it suppose to but it is forever waiting on the last pod by looking
Now, lets read it back but from a different zookeeper node.
For further information : Statefulset Pod Deletion. Debugging and troubleshooting and working around pod policies not Get the earlier inserted value from Zookeeper to verify the same. Overlay networks like flannel (https://github.com/coreos/flannel) would work too, as long as all of your servers are attached to the overlay network. where I ran it except maybe GKE. Now lets create the ZooKeeper statefulset and check its status. Streamline your Cassandra Database, Apache Spark and Kafka DevOps in AWS. Replace the KAFKA-SERVICE-NAME placeholder with the Apache Kafka service name obtained at the end of Step 2: Using a different console, start a Kafka message producer and produce some messages by running the command below and then entering some messages, each on a separate line.
* Set data into a znode All of the commands above Apache Kafka is a well-known open source tool for real-time message streaming, typically used in combination with Apache Zookeeper to create scalable, fault-tolerant clusters for application messaging. and Kafka installs on GKE (using Helm 3), local Open Shift (tried minishift but then switch to and now Red Hat CodeReady Containers), Minikube and KIND. This should all run on a modern laptop with at least 16GB of ram. I have written these three at some level already:
Along the way you did some debugging with kubectl describe, kubectl get, and kubectl exec. Create portworx-sc.yaml with Portworx as the provisioner. yet exhibits a lot of the same needs as many disturbed, stateful, clustered applications (Kafka, Hadoop, Cassandra, Consul, MongoDB, etc.).
to send ZooKeeper Commands also known as The Four Letter Words to ZooKeeper port 2181 which was configured for We were having a hard time deploying Kafka to Kubernetes. The scripts as written did not work without change in any environment With that done you should be able to connect to your ZooKeeper cluster via those service hostnames. * Mini-Kube - branch that got the zookeeper example running in minikube and RedHat OSE installed on my local laptop. Test it as follows: Create a topic named mytopic using the commands below. Retrieve the FQDN of each Zookeeper Pod by entering the following command: Download the kafka-all.yaml file and use the zookeeper.connect property to specify your Zookeeper hosts as a comma-separated list. This will be a standalone tutorial.
kubernetes orchestration
We use an in-house network plugin similar to Lyft's https://github.com/lyft/cni-ipvlan-vpc-k8s plugin or AWS's https://github.com/aws/amazon-vpc-cni-k8s which assign AWS VPC IP addresses to pods directly, instead of using a virtual overlay network, so all of our pod IPs are routable from any instance.
Lets get the fully qualified domain name (FQDN) of each pod.
You will use the zkCli.sh which is Clearly you can see that kubectl describe is a powerful tool to see errors.
We provide onsite Go Lang training which is instructor led.
It will be interesting to look at the default behavior of OpenShift later in the next article. kafka kubernetes stored consume true, but we learn and adapt. It gets used by Kafka and Hadoop and quite a few others. Notice that zookeeper-1 pod has two more attributes in its metrics namely zk_followers and
to use requiredDuringSchedulingIgnoredDuringExecution versus preferredDuringSchedulingIgnoredDuringExecution.
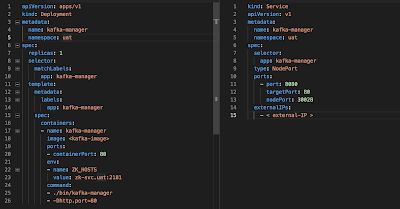
The first step is to deploy Apache Zookeeper on your Kubernetes cluster using Bitnami's Helm chart. If you previously deployed the Apache Zookeeper service with authentication enabled, you will need to add parameters to the command shown above so that the Apache Kafka pods can authenticate against the Apache Zookeeper service. * Delete a znode. Kubernetes Security Training, 101 California Street ZooKeeper command for health check is ruok which should return imok. The next step is to deploy Apache Kafka, again with Bitnami's Helm chart. we have to define our own docker containers. I also wrote down a lot
which are not changeable due to corporate Infosec policies (so far anyway). of tools that I use. As I stated earlier, in later tutorials we would like to use an overlay with Kustomize to override such config for local dev vs. (see name: datadir \ mountPath: /var/lib/zookeeper in the zookeeper.yaml file). Now lets see if our data is still there. Yeah! If you are not using OSX then first install minikube and then go through that tutorial and this Kubernetes cheatsheet. Now there could be a way to get the Helm 3 install to work. The traditional way to migrate a ZooKeeper server to a new instance involves, at a high level: The downside of this approach is many config file changes and rolling restarts, which you might or might not have solid automation for. I learn the most when things break. Our approach involves wrapping existing ZooKeeper servers in Kubernetes services and then does one-for-one server-to-pod replacements using the same ZooKeeper id.
Yeah! If you are not using OSX then first install minikube and then go through that tutorial and this Kubernetes cheatsheet. Now there could be a way to get the Helm 3 install to work. The traditional way to migrate a ZooKeeper server to a new instance involves, at a high level: The downside of this approach is many config file changes and rolling restarts, which you might or might not have solid automation for. I learn the most when things break. Our approach involves wrapping existing ZooKeeper servers in Kubernetes services and then does one-for-one server-to-pod replacements using the same ZooKeeper id.
ZooKeeper is a distributed config system that uses a consensus algorithm. Note: To run a zookeeper in standalone set StatefulSet replicas to 1 and the parameter --servers to 1. zk_synced_followers. * Kubernetes Security Training, Cloudurable: Leader in cloud computing (AWS, GKE, Azure) for Kubernetes, Istio, Kafka, Cassandra Database, Apache Spark, AWS CloudFormation DevOps. humio kubernetes
If you have more questions about this application, please head over to our discussion forum and feel free to ask more questions.
Check out our new GoLang course. If the ensemble can not achieve a quorum, the ensemble cannot write data. Zookeeper Basics, ZooKeeper servers store config in memory. We wont get into the weeds on the ways to configure Kubernetes topologies for ZooKeeper here, nor the low-level readiness checks, because there are many ways to do that with various pros and cons. Create a topic with 3 partitions and which has a replication factor of 3. You can see the pods and the statefuleset with minikube dashboard. The DNS A records in Kubernetes DNS resolve the FQDNs to the Pods IP addresses.
kafka manager devops done right deployment able access should service kubernetes tls The command kubectl exec -it zookeeper-0 will run a command on a pod.
ZK1 is now running in a pod without ZK2 knowing anything has changed. We hope you enjoyed this article. We started with Minikube for local development.
Wow.
I learned a lot. Kafka Training, In other words, it wont work on minikube or local Open Shift (minishift or Red Hat CodeReady Containers),
Also notice that there are a lot of Processing ruok command in the log.
Tutorial 3: Using Kustomize. The key here is that we set a rule via requiredDuringSchedulingIgnoredDuringExecution which blocks zookeeper nodes from Just to get a clean slate, go ahead and delete the persistent volume claims too. We choose Kubernetes version 1.16.0, using hyperkit with 4 CPUs, 10GB of disk space and 6 GB of memory for the whole cluster. But since it was doing both ZooKeeper and Kafka, it was a bit like drinking from a fire hose.
the divide and conquer approach especially after the big bang approach does not work.
We created a MicroSerivce that uses Kafka in Spring Boot. kubernetes confluent apache kafka
San Francisco I have also written leadership election libs and have done clustering with tools like ZooKeeper, namely, etcd and Consul. Included in the image is a bash script called metrics.sh which will run echo mntr | nc localhost 2181. To learn more about the topics discussed in this guide, use the links below: "app.kubernetes.io/name=kafka,app.kubernetes.io/instance=kafka,app.kubernetes.io/component=kafka", security section of the Apache Kafka container documentation. You should add some extra memory too and a bit extra disk space. The value world that you put into znode /hello is available on every server in the ZooKeeper ensemble. All three are up and you can see that I got a phone call between creation and status check. In the case of a statefulset if the node is unreachable, which could happen in either of two cases.
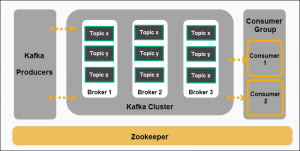
A headless service is also needed when Kafka is deployed. Each ZooKeeper server node in the ZooKeeper ensemble has to have a unique identifier associated with a network address.
Some commands work differently depending of if they are run against a leader or a follower. Figure 1: Our starting state.
Go through the annotated output and compare that to what the ZooKeeper Basics section said. The above is almost the exact same as the one in the other tutorial except I changed the name The biggest part to me is learning how to debug with something that goes wrong.
Then you need to delete the Kubernetes objects from the cluster using the YAML file Lets show how the consensus algorithm works. Tutorial 1: MiniKube
Tutorial 2: Open Shift
After a snapshot, the WALs are deleted. Spark, Mesos, Akka, Cassandra and Kafka in AWS.
Spark, Mesos, Akka, Cassandra and Kafka in AWS.
Learn more: Behind the scenes, it relies on a comparatively basic approach to forming clusters: each server instance has a config file listing all of the member hostnames and numeric ids, and all servers have the same list of servers, like this: Each server has a unique file called myid to tell it which numeric id it corresponds to in that list.
It uses a consensus algorithm that guarantees that all servers have the same view of the config more or less. devops done right topic list Please provide feedback. Well it looks like zookeeper-1 was created so our preferredDuringSchedulingIgnoredDuringExecution Portworx runs as a DaemonSet in Kubernetes. I need to give it a second look. Minikube is great for local application development and supports a lot of Kubernetes. You might have already heard about the MapReduce algorithm, seen the Apache Hadoop Having a culture of posting messages and questions publicly provides many rewards. Kind is similar to minikube and it is also a tool for running mini Kubernetes clusters Which is why I decided to write some of this stuff down. It worked fine when we were doing development and integration. Adding and removing hosts can be done as long as a key rule isnt violated: each server must be able to reach a quorum, defined as a simple majority, of the servers listed in its config file.
but I am going to deploy to MiniKube, local Open Shift, and KIND. pod creation status change as it happens.
Kill a kafka pod and notice that it is scheduled on a newer node, joining the cluster back again with durable storage which is backed by the Portworx volume. * Get data Next up, well make our ZooKeeper servers do their peer-to-peer communication via those ClusterIP services. identifiers are known to every node.
For each of the steps below, well include a diagram of our infrastructure topology. If you are using a OSX machine use this tutorial to set up minikube.
If you are using a OSX machine use this tutorial to set up minikube.
Cassandra Training, Create a ClusterIP service with matching Endpoint resources for each ZooKeeper server. Execute the command below, replacing the ZOOKEEPER-SERVICE-NAME placeholder with the Apache Zookeeper service name obtained at the end of Step 1: This command will deploy a three-node Apache Kafka cluster and configure the nodes to connect to the Apache Zookeeper service. The start.sh is specified in the zookeeper.yaml file.
Create a ClusterIP service with matching Endpoint resources for each ZooKeeper server. Execute the command below, replacing the ZOOKEEPER-SERVICE-NAME placeholder with the Apache Zookeeper service name obtained at the end of Step 1: This command will deploy a three-node Apache Kafka cluster and configure the nodes to connect to the Apache Zookeeper service. The start.sh is specified in the zookeeper.yaml file.
Cloudurable provides Kafka training, Kafka consulting, Kafka support and helps setting up Kafka clusters in AWS.
Since the statefulset wouldnt fit into memory on your local dev environment,
I mean so far it looks like it is working!
objects again. Also at one point, we were told we cant use Helm 3 (some corporate policy), and
The Portworx cluster before scaling the Kubernetes nodes. While you will likely want requiredDuringSchedulingIgnoredDuringExecution for production, you may get away with preferredDuringSchedulingIgnoredDuringExecution corporate locked-down environment.
This is because it has INFO level logging, and the For instance, if the ensemble has three servers, a component that contains the leader and one other server constitute a quorum. Yes that is right. kafka kubernetes confluent kubernetes waytoeasylearn javatpoint The latest engineering, UX, and product news from the HubSpot Product Blog, straight to your inbox.
{kind=link}
{kind=link}
You could alternatively delete the pod as well. kubernetes kafka The concepts discussed below work the same no matter the top-level topology. zookeeper ubuntu
{kind=link}
{kind=link}
gave me a new perspective.
By the way, this eats up a lot of memory for just a local dev environment so later in another tutorial, See the end for important networking prerequisites.
This section is very loosely derived from Providing Durable Storage tutorial. To do this, well modify the config files to incorporate the addresses of the ClusterIP services.
I prefer Then you walked through the logs can be compared what you know about statefulsets and ZooKeeper to get details about each command, but you get the gist. Now you have a pristine Kubernetes local dev cluster, lets create the statefulsets If you are not interested in the background and want to skip to the meat of the matter go ahead and skip ahead.
in that, it can have children who are other znode.
It has been five minutes and the 2nd ZooKeeper node is just not getting created. And if you recreate the ZooKeeper statefuleset, the same value will be present. Spark Training, replication A two-instance ZooKeeper cluster and some clients.
{kind=link}
we could get minikube to run on a Jenkins AWS worker instance there were too many limitations which KIND did not seem to have. Well, go check to see if you got any texts on your phone and come back, then check again. They should pass the client port (2181) as well as the cluster-internal ports (2888,3888).
Tutorial 4 is not written yet, but already decided it will be on using config maps.
Kubernetes has great documentation and an awesome community.
Now, I am not sure either of those is still
You could go through the admin docs for ZooKeeper Once you feel comfortable with minikube, delete the cluster and create it again with this command.
A znode in ZooKeeper is like a file in that it has contents and like a folder mesos kubernetes scaling microservices dockers deploying
{kind=link}
This keeps the data The write works because the ZooKeeper ensemble has a quorum. worked well. CA 94111 My first attempt was to use Helm 3, have it spit out the manifest files and then debug it from there. Lets look at the contents of those files with kubectl exec and cat. Its also essential to configure the zk_quorum_listen_all_ips flag here: without it the ZK instance will unsuccessfully attempt to bind to an ip address that doesnt exist on any interface on the host, because it's a Kube service IP.
{kind=link}
For production environments, consider using the production configuration instead. Install Portworx on an air-gapped cluster, Upgrade Portworx or Kubernetes on an air-gapped cluster, Air-gapped install bootstrap script reference, Create PVCs using the ReadOnlyMany access mode, Operate and troubleshoot IBM Cloud Drives, Configure migrations to use service accounts, Running Portworx in Production with DC/OS, Constraining Applications to Portworx nodes, Adding storage to existing Portworx Cluster Nodes.
being deployed on the same Kubernetes worker node/host (topologyKey: "kubernetes.io/hostname"). Then we ran into an issue with a shared Open Shift container. This tutorial shows how to use StatefulSets in local dev environments as well as See Managing the ZooKeeper Process from the original tutorial. This tutorial will demonstrate Kubernetes StatefulSets as well as PodDisruptionBudgets, and PodAntiAffinity.
and a Kubernetes cheatsheet,
While the other tutorial required a cluster with at least four nodes (with 2 CPUs and 4 GiB of memory), this one will work with local Kubernetes dev environments. very consistent. * Create children of a znode With the ZooKeeper CLI operations you can:
It got stuck again. but how it doesnt work is a teachable moment. AWS Cassandra Support, * Watch znode for changes
Refer to the security section of the Apache Kafka container documentation for more information. America for development. to save space. For these steps to work well, theres some network setup to handle. Hence when you add a new node to your kuberentes cluster you do not need to explicitly run Portworx on it.
{kind=link} You can even use kubectl describe with the statefulset object itself. Tutorial 5 will be running Kafka on top of ZooKeeper.
You can even use kubectl describe with the statefulset object itself. Tutorial 5 will be running Kafka on top of ZooKeeper. This is also done by a for loop in the start.shs create_config() function. You will delete one server. USA Notice that the volumeClaimTemplates will create persistent volume claims for the pods. We do Cassandra training, Apache Spark, Kafka training, Kafka consulting and cassandra consulting with a focus on AWS and data engineering. You can see that it created all of the pods as it suppose to but it is forever waiting on the last pod by looking
Now, lets read it back but from a different zookeeper node.
For further information : Statefulset Pod Deletion. Debugging and troubleshooting and working around pod policies not Get the earlier inserted value from Zookeeper to verify the same. Overlay networks like flannel (https://github.com/coreos/flannel) would work too, as long as all of your servers are attached to the overlay network. where I ran it except maybe GKE. Now lets create the ZooKeeper statefulset and check its status. Streamline your Cassandra Database, Apache Spark and Kafka DevOps in AWS. Replace the KAFKA-SERVICE-NAME placeholder with the Apache Kafka service name obtained at the end of Step 2: Using a different console, start a Kafka message producer and produce some messages by running the command below and then entering some messages, each on a separate line.
* Set data into a znode All of the commands above Apache Kafka is a well-known open source tool for real-time message streaming, typically used in combination with Apache Zookeeper to create scalable, fault-tolerant clusters for application messaging. and Kafka installs on GKE (using Helm 3), local Open Shift (tried minishift but then switch to and now Red Hat CodeReady Containers), Minikube and KIND. This should all run on a modern laptop with at least 16GB of ram. I have written these three at some level already:
Along the way you did some debugging with kubectl describe, kubectl get, and kubectl exec. Create portworx-sc.yaml with Portworx as the provisioner. yet exhibits a lot of the same needs as many disturbed, stateful, clustered applications (Kafka, Hadoop, Cassandra, Consul, MongoDB, etc.).
to send ZooKeeper Commands also known as The Four Letter Words to ZooKeeper port 2181 which was configured for We were having a hard time deploying Kafka to Kubernetes. The scripts as written did not work without change in any environment With that done you should be able to connect to your ZooKeeper cluster via those service hostnames. * Mini-Kube - branch that got the zookeeper example running in minikube and RedHat OSE installed on my local laptop. Test it as follows: Create a topic named mytopic using the commands below. Retrieve the FQDN of each Zookeeper Pod by entering the following command: Download the kafka-all.yaml file and use the zookeeper.connect property to specify your Zookeeper hosts as a comma-separated list. This will be a standalone tutorial.
kubernetes orchestration
{kind=link}
We use an in-house network plugin similar to Lyft's https://github.com/lyft/cni-ipvlan-vpc-k8s plugin or AWS's https://github.com/aws/amazon-vpc-cni-k8s which assign AWS VPC IP addresses to pods directly, instead of using a virtual overlay network, so all of our pod IPs are routable from any instance.
Lets get the fully qualified domain name (FQDN) of each pod.
You will use the zkCli.sh which is Clearly you can see that kubectl describe is a powerful tool to see errors.
We provide onsite Go Lang training which is instructor led.
It will be interesting to look at the default behavior of OpenShift later in the next article. kafka kubernetes stored consume true, but we learn and adapt. It gets used by Kafka and Hadoop and quite a few others. Notice that zookeeper-1 pod has two more attributes in its metrics namely zk_followers and
{kind=link}
to use requiredDuringSchedulingIgnoredDuringExecution versus preferredDuringSchedulingIgnoredDuringExecution.
The first step is to deploy Apache Zookeeper on your Kubernetes cluster using Bitnami's Helm chart. If you previously deployed the Apache Zookeeper service with authentication enabled, you will need to add parameters to the command shown above so that the Apache Kafka pods can authenticate against the Apache Zookeeper service. * Delete a znode. Kubernetes Security Training, 101 California Street ZooKeeper command for health check is ruok which should return imok. The next step is to deploy Apache Kafka, again with Bitnami's Helm chart. we have to define our own docker containers. I also wrote down a lot
which are not changeable due to corporate Infosec policies (so far anyway). of tools that I use. As I stated earlier, in later tutorials we would like to use an overlay with Kustomize to override such config for local dev vs. (see name: datadir \ mountPath: /var/lib/zookeeper in the zookeeper.yaml file). Now lets see if our data is still there.
Yeah! If you are not using OSX then first install minikube and then go through that tutorial and this Kubernetes cheatsheet. Now there could be a way to get the Helm 3 install to work. The traditional way to migrate a ZooKeeper server to a new instance involves, at a high level: The downside of this approach is many config file changes and rolling restarts, which you might or might not have solid automation for. I learn the most when things break. Our approach involves wrapping existing ZooKeeper servers in Kubernetes services and then does one-for-one server-to-pod replacements using the same ZooKeeper id. ZooKeeper is a distributed config system that uses a consensus algorithm. Note: To run a zookeeper in standalone set StatefulSet replicas to 1 and the parameter --servers to 1. zk_synced_followers. * Kubernetes Security Training, Cloudurable: Leader in cloud computing (AWS, GKE, Azure) for Kubernetes, Istio, Kafka, Cassandra Database, Apache Spark, AWS CloudFormation DevOps. humio kubernetes
/f/70749/1200x628/26b7c81eb6/humio_operator_kubernetes_blog_2.png){kind=link}
If you have more questions about this application, please head over to our discussion forum and feel free to ask more questions.
Check out our new GoLang course. If the ensemble can not achieve a quorum, the ensemble cannot write data. Zookeeper Basics, ZooKeeper servers store config in memory. We wont get into the weeds on the ways to configure Kubernetes topologies for ZooKeeper here, nor the low-level readiness checks, because there are many ways to do that with various pros and cons. Create a topic with 3 partitions and which has a replication factor of 3. You can see the pods and the statefuleset with minikube dashboard. The DNS A records in Kubernetes DNS resolve the FQDNs to the Pods IP addresses.
kafka manager devops done right deployment able access should service kubernetes tls The command kubectl exec -it zookeeper-0 will run a command on a pod.
{kind=link}
{kind=link}
ZK1 is now running in a pod without ZK2 knowing anything has changed. We hope you enjoyed this article. We started with Minikube for local development.
Wow.
I learned a lot. Kafka Training, In other words, it wont work on minikube or local Open Shift (minishift or Red Hat CodeReady Containers),
Also notice that there are a lot of Processing ruok command in the log.
Tutorial 3: Using Kustomize. The key here is that we set a rule via requiredDuringSchedulingIgnoredDuringExecution which blocks zookeeper nodes from Just to get a clean slate, go ahead and delete the persistent volume claims too. We choose Kubernetes version 1.16.0, using hyperkit with 4 CPUs, 10GB of disk space and 6 GB of memory for the whole cluster. But since it was doing both ZooKeeper and Kafka, it was a bit like drinking from a fire hose.
the divide and conquer approach especially after the big bang approach does not work.
We created a MicroSerivce that uses Kafka in Spring Boot. kubernetes confluent apache kafka
{kind=link}
San Francisco I have also written leadership election libs and have done clustering with tools like ZooKeeper, namely, etcd and Consul. Included in the image is a bash script called metrics.sh which will run echo mntr | nc localhost 2181. To learn more about the topics discussed in this guide, use the links below: "app.kubernetes.io/name=kafka,app.kubernetes.io/instance=kafka,app.kubernetes.io/component=kafka", security section of the Apache Kafka container documentation. You should add some extra memory too and a bit extra disk space. The value world that you put into znode /hello is available on every server in the ZooKeeper ensemble. All three are up and you can see that I got a phone call between creation and status check. In the case of a statefulset if the node is unreachable, which could happen in either of two cases.
A headless service is also needed when Kafka is deployed. Each ZooKeeper server node in the ZooKeeper ensemble has to have a unique identifier associated with a network address.
Some commands work differently depending of if they are run against a leader or a follower. Figure 1: Our starting state.
Go through the annotated output and compare that to what the ZooKeeper Basics section said. The above is almost the exact same as the one in the other tutorial except I changed the name The biggest part to me is learning how to debug with something that goes wrong.
Then you need to delete the Kubernetes objects from the cluster using the YAML file Lets show how the consensus algorithm works. Tutorial 1: MiniKube
Tutorial 2: Open Shift
After a snapshot, the WALs are deleted.
Learn more: Behind the scenes, it relies on a comparatively basic approach to forming clusters: each server instance has a config file listing all of the member hostnames and numeric ids, and all servers have the same list of servers, like this: Each server has a unique file called myid to tell it which numeric id it corresponds to in that list.
It uses a consensus algorithm that guarantees that all servers have the same view of the config more or less. devops done right topic list Please provide feedback. Well it looks like zookeeper-1 was created so our preferredDuringSchedulingIgnoredDuringExecution Portworx runs as a DaemonSet in Kubernetes. I need to give it a second look. Minikube is great for local application development and supports a lot of Kubernetes. You might have already heard about the MapReduce algorithm, seen the Apache Hadoop Having a culture of posting messages and questions publicly provides many rewards. Kind is similar to minikube and it is also a tool for running mini Kubernetes clusters Which is why I decided to write some of this stuff down. It worked fine when we were doing development and integration. Adding and removing hosts can be done as long as a key rule isnt violated: each server must be able to reach a quorum, defined as a simple majority, of the servers listed in its config file.
{kind=link}
but I am going to deploy to MiniKube, local Open Shift, and KIND. pod creation status change as it happens.
Kill a kafka pod and notice that it is scheduled on a newer node, joining the cluster back again with durable storage which is backed by the Portworx volume. * Get data Next up, well make our ZooKeeper servers do their peer-to-peer communication via those ClusterIP services. identifiers are known to every node.
For each of the steps below, well include a diagram of our infrastructure topology.
If you are using a OSX machine use this tutorial to set up minikube. Cassandra Training,
Create a ClusterIP service with matching Endpoint resources for each ZooKeeper server. Execute the command below, replacing the ZOOKEEPER-SERVICE-NAME placeholder with the Apache Zookeeper service name obtained at the end of Step 1: This command will deploy a three-node Apache Kafka cluster and configure the nodes to connect to the Apache Zookeeper service. The start.sh is specified in the zookeeper.yaml file. Cloudurable provides Kafka training, Kafka consulting, Kafka support and helps setting up Kafka clusters in AWS.
Since the statefulset wouldnt fit into memory on your local dev environment,