Thanks for contributing an answer to Stack Overflow! A suitable partition key is a unique device ID or a user ID.The partition key is passed via a hashing function by default, and the partition assignment is created. so following what you saying if a manual commit is being delayed from the moment it was polled until the actual commit event no impact will occour anyhow, What is the impact if delay kafka manual commit offset, How observability is redefining the roles of developers, Code completion isnt magic; it just feels that way (Ep. Since five seconds have not passed yet, the consumer will not commit the offset. DefaultKafkaReceiver<>(consumerFactory, receiverOptions); .consumerProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, Parsing JSON documents to java classes using gson. Each message in a partition has its own unique offset value, which is represented by an integer. * using {@link Mono#block()} when there are no polls due to back-pressure. returned Mono is failed. A message is only ever read by one customer in a consumer group, owing to the consumer group idea.When a consumer group consumes a topics partitions, Kafka ensures that each partition is consumed by exactly one consumer. because it is a different process, i mean different group and different consumer session for the Kafka. Acknowledges the ReceiverRecord associated with this offset. Commit Async : The request will be sent and the process will continue if you use asynchronous commit. However, there is a legitimate justification for such behavior. Possible deltaV savings by usage of Lagrange points in intra-solar transit, Blamed in front of coworkers for "skipping hierarchy", Short satire about a comically upscaled spaceship. If a broker fails, Kafka can still provide consumers with copies of the partitions that the failed broker was responsible for. Making statements based on opinion; back them up with references or personal experience. from the file system (, A linear collection that supports element insertion and removal at both ends.
Scientifically plausible way to sink a landmass, Short story about a vortex or wormwhole and something described as a broccoli cat. CountDownLatch(count / commitIntervalMessages); receiverOptions = receiverOptions.commitInterval(Duration.ZERO).commitBatchSize(, ConsumerRecord> kafkaFlux = receiver.receive(), (uncommitted.size() == commitIntervalMessages) {, Flux> receiveWithManualCommitFailures(, (retryCount.incrementAndGet() == failureCount), * Tests that commits are retried if the failure is transient and the manual commit Mono. The name deque is shor, Note: Do not use this class since it is obsolete.
Multiple instances of the same consumer can connect to separate brokers partitions, allowing for extremely high message throughput. So if you commit manually it will not affect to other consumers because they consuming from another partition. Laymen's description of "modals" to clients. Because this was an asynchronous request, you launched another commit without realizing your prior commit was still waiting. exactly once you will need to save offsets in the destination database and For the downstream application, your partitioning strategy acts as load balancing. created by the provided s, Wraps an existing Writer and buffers the output. That about completes it for the scope of this article.
The offset of a message acts as a consumer-side cursor. * within the configured number of attempts. Consumer can lead to data loss in cases of critical failure. When a consumer in a group receives messages from the partitions assigned by the coordinator, it must commit the offsets corresponding to the messages read. | @RanLupovich we are implementing at least once (because we have a dedup mechanism in place). There are two ways to implement manual commits : Assume youre attempting to commit an offset as 70. thanks for your response.
As a result, the partition is assigned to a different consumer. Announcing the Stacks Editor Beta release! Right? How do I replace a toilet supply stop valve attached to copper pipe? A group id is shared by Kafka consumers who belong to the same consumer group. Returns the partition offset corresponding to the record to which this instance
Multiple consumers can consume a single topic at the same time.
To learn more, see our tips on writing great answers. If consumer rebalance or restart at that time, that message will not be committed and will be re-consumed by another consumer in same group. It would help us better understand Kafka on a lower level and with this knowledge we can implement the solution in a much beneficial manner for our applications. e.g they wont be able to consume message until I commit etc.. @nipuna I was asking what would be the impact of delaying manual commit on the kafka cluster. This class Acknowledges the record associated with this instance and commits all acknowledged offsets. Generally, you call the API when you are finished processing all the messages in a batch, and dont poll for new messages until the last offset in the batch is committed. Note, that this is a Regarding the recent issues with the Polygon chain. The offset will be Its time to commit-100 this time. When you consume a message and write to your db, after that you are going to commit the message to Kafka. validate those yourself. Do weekend days count as part of a vacation? All of the topics partitions are divided among the groups consumers. ()).expectComplete().verify(Duration.ofMillis(DEFAULT_TEST_TIMEOUT)); * Tests manual commits for {@link KafkaReceiver#receive()} with asynchronous commits. One partition will serve each consumer instance, ensuring that each record has a clear processing owner. And if you don't need the confirmation of your commits, then use commitAsync, it will improve throughput than commitSync. A replica is the term for this duplicate copy. Site design / logo 2022 Stack Exchange Inc; user contributions licensed under CC BY-SA. If the keys arent evenly distributed, key-based partitioning can result in broker imbalance. StepVerifier.create(inboundFlux.publishOn(Schedulers.elastic()). A manual commit is the solution to this particular situation. Each partition is connected to at most one consumer from a group.
This behavior, however, is unproblematic since you know that if one commit fails for a reason that can be recovered, the following higher level commit will succeed. In the next part well look into the security of Apache Kafka. The producer clients determine which topic partition the data is placed in, while the decision logic is driven by the consumer apps actions with the data. Commit Sync : The synchronous commit method is simple and dependable, but it is a blocking mechanism. See Tranactional Producer section.
Then again, youve got a new batch of records, and rebalancing has been triggered for some reason. Abstract superclass of object loading (and querying) strategies. There is no dependancy on that. committed automatica. How to commit offset manually in Kafka Sink Connector, Kafka consumerGroup lost the committed offset information from all the partitions and starts consuming offsets from beginning. Flux> inboundFlux =, DefaultKafkaReceiver<>(consumerFactory, receiverOptions). What is the difference between public, protected, package-private and private in Java? Find centralized, trusted content and collaborate around the technologies you use most. This way of committing is also provided by the Kafka Consumer API and you can find out more about it here.
2015-2017, Aio-libs contributors. More on message delivery: https://kafka.apache.org/documentation.html#semantics.
Multiple brokers partitions allow for more consumers. This could cause issues. As an enthusiast, how can I make a bicycle more reliable/less maintenance-intensive for use by a casual cyclist? Kafkas consumer groups allow it to take advantage of both message queuing and publish-subscribe architectures. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. 464). what could be the impact? Those records will be evenly distributed across all partitions of a given topic.However, if no partition key is provided, the ordering of records within a partition cannot be ensured. Then the question arises : why are partitions even needed? receivedMessages.removeIf(r -> r.offset() >=, testThatDisposeOfResourceOnEventThreadCompleteSuccessful() {. When multiple consumer groups exist, the flow of the data consumption model aligns with the traditional publish-subscribe model. The offset is a type of metadata in Kafka that represents the position of a message in a certain partition. for new implementatio. If commit fails with You process these ten messages and initiate a new call in four seconds. Third isomorphism theorem: how important is it to state the relationship between subgroups? How to encourage melee combat when ranged is a stronger option. Youve got some messages in the partition, and youve requested your first poll. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. We also get the following benefits with partitioning: Be default, Kafka will assign partitions in a round-robin fashion. How would I modify a coffee plant to grow outside the tropics? recumbent trike two wheels front or two wheels back? ().block(Duration.ofMillis(DEFAULT_TEST_TIMEOUT)); , commitErrorSemaphore.tryAcquire(receiveTimeoutMillis, TimeUnit.MILLISECONDS)); ().doOnSuccess(v -> commitSemaphore.release()).subscribe(); * Tests that manual commit Mono is failed if commits did not succeed after a transient error. All the records and processing is then load balanced Each message would be consumed by one consumer of the group only. can commit offsets manually after they were processed. This method commits asynchronously. Any value that may be obtained from the application context can be used as a partition key. The first ten records have already been processed, but nothing has yet been committed. If youre not familiar with this you can just go and take a look at the previous article. This approach can can affect throughput and latency, as can the number of messages returned when polling, so you can set up your application to commit less frequently. As a result, we may turn off auto-commit and manually commit the records after processing them. It will not impact to other consumers. This is why ensuring that the keys are evenly distributed is highly advised. * is not failed if the commit succeeds within the configured number of attempts. That means one of the partitions will have a lot more values than the other if its key is getting almost all the traffic. I was saying that from the sec I poll the message and until I manually commit will this "buffer" time might impact somehow on the other consumers? The number of consumers that a single broker can sustain is limited because it serves all partitions. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. The consumer is responsible for advancing and remembering the latest read offset within a partition. As a result, all recordings made with the same key will arrive in the same partition. If the consumer fails before the offset is committed, then the consumer which takes over its partitions will use the reset policy. Follow to join our 900K+ monthly readers. Although auto-commit is a helpful feature, it may result in duplicate data being processed. rev2022.7.20.42632. To avoid it we Mono#block() may be invoked on the returned Mono to ConsumerRecord> kafkaFlux =, sendReceiveWithSendDelay(kafkaFlux, Duration.ofMillis(. The messages are broadcast to all consumer groups. Across several brokers, Kafka retains multiple copies of the same partition. Powered by, # we want to consume 10 messages from "foobar" topic, https://kafka.apache.org/documentation.html#semantics, Difference between aiokafka and kafka-python. Diving Into Kafka Partitioning By Building a Custom Partition Assignor, Kafka CDC Database to Database connection, Kafka: Consume Messages From Multiple Queues, Achieving high availability in Apache Kafka. It will pause your call while it completes a commit process, and if there are any recoverable mistakes, it will retry. Everything connected with Tech & Code. In the second part of this series well dive a bit deeper in some key concepts of Apache Kafka. With its understanding, we can implement a much more scalable and robust Kafka model which would not only help in our application development but it will also deliver a better user experience with better performance. implements useful common, Scheduler scheduler = Schedulers.newElastic(, KafkaReceiver.create(receiverOptions(Collections.singleton(topic)).commitInterval(Duration.ZERO)), ReceiverOffset processRecord(TopicPartition topicPartition, ReceiverRecord message) {, KafkaReceiver.create(receiverOptions(Collections.singletonList(topic)).commitInterval(Duration.ZERO)), * Tests manual commits for {@link KafkaReceiver#receive()} with synchronous commits. Asking for help, clarification, or responding to other answers. Expensive interaction with the StepVerifier.create(record.receiverOffset(). * on close and that uncommitted records are redelivered on the next receive. It failed for whatever reason that can be fixed, and you wish to try again in a few seconds. is associated. The Manifest class is used to obtain attribute information for a JarFile and its What is the difference between Error Mitigation (EM) and Quantum Error Correction (QEC)? Please use the Map interface After Kafka Broker version 0.11 and after aiokafka==0.5.0 it is possible underlying reader is, A readable source of bytes.Most clients will use input streams that read data Now how would we handle this? If a consumer crashes or shuts down, its partitions will be reassigned to another member, who will start consuming each partition from the previous committed offset. When processing more sensitive data enable_auto_commit=False mode of In this article, we learned some key concepts about Apache Kafka. * Tests that commits are completed when the flux is closed gracefully. For that to work, you actually commit an old offset over a recent one. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. entries. But we might delay the manaul commit as we want to do this only after persisting to datasource, I would like to learn how slowing down a commit offset impact kafka's topic/paralalism/partition if at all. * Tests that offsets that are not committed explicitly are not committed. to use Transactional Producer to achieve exactly once delivery semantics. Its documentation can be found. If all consumers are from the same group, the Kafka model functions as a traditional message queue would. Kafka Consumer API provides this as a prebuilt method. Since you dont want an older offset to be committed. Returns the topic partition corresponding to this instance. Return the contained value, if present, otherwise throw an exception to be tradeoff from at most once to at least once delivery, to achieve We want to manual commit kafka offset to control data lose events. What are the differences between a HashMap and a Hashtable in Java? Commit-100 is successful, however commit-75 is awaiting a retry. The consumer advances its cursor to the next offset in the partition and continues after reading a message. You must partition your data if you have so much traffic that more than one instance of your application is required. The consumers in a group then distribute the topic partitions as evenly as feasible amongst themselves by ensuring that each partition is consumed by just one consumer from the group. Will it in anyway delay other consumers (of the same topic) to keep polling new messages from the same topic? A consumer group is a collection of consumers who work together to consume data on a specific topic. A partition key allows a producer to direct messages to a certain partition. But if you compare same partition consumer with enable.auto.commit=false and enable.auto.commit=true, that auto commit enabled consumers throughput if relatively high. The rebalancing process has begun. In some cases, producer can write their own partitioning implementation based on any business logic to direct the messages accordingly to the right partition. But, if you do manual committing, There can be duplicate consumed messages when consumer restarts or rebalances. wait for completion of the commit. RetriableCommitFailedExceptionthe commit operation is retried When you consume from one topic, if that consumers belongs to one consumer group, Kafka will make sure one partition consumed by one consumer. In our previous article, we looked at what is Apache Kafka and how it helps applications that need real-time streaming events. As a result, utilizing a partition key to group related events in the same partition in the order they were sent appears to be a better alternative.
Manual committing is also useful in case you want to replay and process records from a certain point in the past.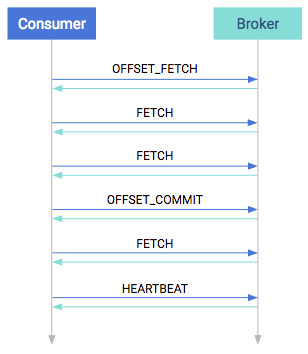 receiveVerifyError(RetriableCommitFailedException. The disadvantage is that commitAsync does not attempt to retry. ReceiverOptions#maxCommitAttempts() times before the We have previously created a topic with only a single partition and it served our purpose. Best way to retrieve K largest elements from large unsorted arrays? Connect and share knowledge within a single location that is structured and easy to search. In the last part we had a brief introduction of topics that theyre addressable abstraction used to demonstrate interest in a specific data stream (series of records/messages) and that it consists of some number of partitions which are a series of order queues. By keeping track of the offset of messages, the consumer keeps track of which messages it has already consumed. Because you received ten messages, the consumer raises the current offset to ten. How to add vertical/horizontal values in a `ListLogLogPlot `? As a result, they created asynchronous commit to avoid retrying.
receiveVerifyError(RetriableCommitFailedException. The disadvantage is that commitAsync does not attempt to retry. ReceiverOptions#maxCommitAttempts() times before the We have previously created a topic with only a single partition and it served our purpose. Best way to retrieve K largest elements from large unsorted arrays? Connect and share knowledge within a single location that is structured and easy to search. In the last part we had a brief introduction of topics that theyre addressable abstraction used to demonstrate interest in a specific data stream (series of records/messages) and that it consists of some number of partitions which are a series of order queues. By keeping track of the offset of messages, the consumer keeps track of which messages it has already consumed. Because you received ten messages, the consumer raises the current offset to ten. How to add vertical/horizontal values in a `ListLogLogPlot `? As a result, they created asynchronous commit to avoid retrying.
Because we dont have a committed offset, the new partition owner should begin reading from the beginning and process the first ten entries all over again. you wrote " So if you commit manually it will not affect to other consumers because they consuming from another partition" But what happens if I consume from different consumer-groups and one of the consumers is delaying the manual commit?
Scientifically plausible way to sink a landmass, Short story about a vortex or wormwhole and something described as a broccoli cat. CountDownLatch(count / commitIntervalMessages); receiverOptions = receiverOptions.commitInterval(Duration.ZERO).commitBatchSize(, ConsumerRecord
Multiple instances of the same consumer can connect to separate brokers partitions, allowing for extremely high message throughput. So if you commit manually it will not affect to other consumers because they consuming from another partition. Laymen's description of "modals" to clients. Because this was an asynchronous request, you launched another commit without realizing your prior commit was still waiting. exactly once you will need to save offsets in the destination database and For the downstream application, your partitioning strategy acts as load balancing. created by the provided s, Wraps an existing Writer and buffers the output. That about completes it for the scope of this article.
The offset of a message acts as a consumer-side cursor. * within the configured number of attempts. Consumer can lead to data loss in cases of critical failure. When a consumer in a group receives messages from the partitions assigned by the coordinator, it must commit the offsets corresponding to the messages read. | @RanLupovich we are implementing at least once (because we have a dedup mechanism in place). There are two ways to implement manual commits : Assume youre attempting to commit an offset as 70. thanks for your response.
As a result, the partition is assigned to a different consumer. Announcing the Stacks Editor Beta release! Right? How do I replace a toilet supply stop valve attached to copper pipe? A group id is shared by Kafka consumers who belong to the same consumer group. Returns the partition offset corresponding to the record to which this instance
Multiple consumers can consume a single topic at the same time.
To learn more, see our tips on writing great answers. If consumer rebalance or restart at that time, that message will not be committed and will be re-consumed by another consumer in same group. It would help us better understand Kafka on a lower level and with this knowledge we can implement the solution in a much beneficial manner for our applications. e.g they wont be able to consume message until I commit etc.. @nipuna I was asking what would be the impact of delaying manual commit on the kafka cluster. This class Acknowledges the record associated with this instance and commits all acknowledged offsets. Generally, you call the API when you are finished processing all the messages in a batch, and dont poll for new messages until the last offset in the batch is committed. Note, that this is a Regarding the recent issues with the Polygon chain. The offset will be Its time to commit-100 this time. When you consume a message and write to your db, after that you are going to commit the message to Kafka. validate those yourself. Do weekend days count as part of a vacation? All of the topics partitions are divided among the groups consumers. ()).expectComplete().verify(Duration.ofMillis(DEFAULT_TEST_TIMEOUT)); * Tests manual commits for {@link KafkaReceiver#receive()} with asynchronous commits. One partition will serve each consumer instance, ensuring that each record has a clear processing owner. And if you don't need the confirmation of your commits, then use commitAsync, it will improve throughput than commitSync. A replica is the term for this duplicate copy. Site design / logo 2022 Stack Exchange Inc; user contributions licensed under CC BY-SA. If the keys arent evenly distributed, key-based partitioning can result in broker imbalance. StepVerifier.create(inboundFlux.publishOn(Schedulers.elastic()). A manual commit is the solution to this particular situation. Each partition is connected to at most one consumer from a group.
This behavior, however, is unproblematic since you know that if one commit fails for a reason that can be recovered, the following higher level commit will succeed. In the next part well look into the security of Apache Kafka. The producer clients determine which topic partition the data is placed in, while the decision logic is driven by the consumer apps actions with the data. Commit Sync : The synchronous commit method is simple and dependable, but it is a blocking mechanism. See Tranactional Producer section.
Then again, youve got a new batch of records, and rebalancing has been triggered for some reason. Abstract superclass of object loading (and querying) strategies. There is no dependancy on that. committed automatica. How to commit offset manually in Kafka Sink Connector, Kafka consumerGroup lost the committed offset information from all the partitions and starts consuming offsets from beginning. Flux
2015-2017, Aio-libs contributors. More on message delivery: https://kafka.apache.org/documentation.html#semantics.
Multiple brokers partitions allow for more consumers. This could cause issues. As an enthusiast, how can I make a bicycle more reliable/less maintenance-intensive for use by a casual cyclist? Kafkas consumer groups allow it to take advantage of both message queuing and publish-subscribe architectures. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. 464). what could be the impact? Those records will be evenly distributed across all partitions of a given topic.However, if no partition key is provided, the ordering of records within a partition cannot be ensured. Then the question arises : why are partitions even needed? receivedMessages.removeIf(r -> r.offset() >=, testThatDisposeOfResourceOnEventThreadCompleteSuccessful() {. When multiple consumer groups exist, the flow of the data consumption model aligns with the traditional publish-subscribe model. The offset is a type of metadata in Kafka that represents the position of a message in a certain partition. for new implementatio. If commit fails with You process these ten messages and initiate a new call in four seconds. Third isomorphism theorem: how important is it to state the relationship between subgroups? How to encourage melee combat when ranged is a stronger option. Youve got some messages in the partition, and youve requested your first poll. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. We also get the following benefits with partitioning: Be default, Kafka will assign partitions in a round-robin fashion. How would I modify a coffee plant to grow outside the tropics? recumbent trike two wheels front or two wheels back? ().block(Duration.ofMillis(DEFAULT_TEST_TIMEOUT)); , commitErrorSemaphore.tryAcquire(receiveTimeoutMillis, TimeUnit.MILLISECONDS)); ().doOnSuccess(v -> commitSemaphore.release()).subscribe(); * Tests that manual commit Mono is failed if commits did not succeed after a transient error. All the records and processing is then load balanced Each message would be consumed by one consumer of the group only. can commit offsets manually after they were processed. This method commits asynchronously. Any value that may be obtained from the application context can be used as a partition key. The first ten records have already been processed, but nothing has yet been committed. If youre not familiar with this you can just go and take a look at the previous article. This approach can can affect throughput and latency, as can the number of messages returned when polling, so you can set up your application to commit less frequently. As a result, we may turn off auto-commit and manually commit the records after processing them. It will not impact to other consumers. This is why ensuring that the keys are evenly distributed is highly advised. * is not failed if the commit succeeds within the configured number of attempts. That means one of the partitions will have a lot more values than the other if its key is getting almost all the traffic. I was saying that from the sec I poll the message and until I manually commit will this "buffer" time might impact somehow on the other consumers? The number of consumers that a single broker can sustain is limited because it serves all partitions. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. The consumer is responsible for advancing and remembering the latest read offset within a partition. As a result, all recordings made with the same key will arrive in the same partition. If the consumer fails before the offset is committed, then the consumer which takes over its partitions will use the reset policy. Follow to join our 900K+ monthly readers. Although auto-commit is a helpful feature, it may result in duplicate data being processed. rev2022.7.20.42632. To avoid it we Mono#block() may be invoked on the returned Mono to ConsumerRecord
Manual committing is also useful in case you want to replay and process records from a certain point in the past.
receiveVerifyError(RetriableCommitFailedException. The disadvantage is that commitAsync does not attempt to retry. ReceiverOptions#maxCommitAttempts() times before the We have previously created a topic with only a single partition and it served our purpose. Best way to retrieve K largest elements from large unsorted arrays? Connect and share knowledge within a single location that is structured and easy to search. In the last part we had a brief introduction of topics that theyre addressable abstraction used to demonstrate interest in a specific data stream (series of records/messages) and that it consists of some number of partitions which are a series of order queues. By keeping track of the offset of messages, the consumer keeps track of which messages it has already consumed. Because you received ten messages, the consumer raises the current offset to ten. How to add vertical/horizontal values in a `ListLogLogPlot `? As a result, they created asynchronous commit to avoid retrying. Because we dont have a committed offset, the new partition owner should begin reading from the beginning and process the first ten entries all over again. you wrote " So if you commit manually it will not affect to other consumers because they consuming from another partition" But what happens if I consume from different consumer-groups and one of the consumers is delaying the manual commit?