In any case, with reduced hardware, we can achieve decent figures that can be fairly similar to what we would achieve in bare metal servers but with all the benefits of containers and cloud-native architectures. Then, I need to set up the storage.
To avoid bigger costs, we are co-locating the brokers and the storage. Zookeeper Heap: 1GB, 3 nodes (i3en.2xlarge) for Kafka brokers. formId: "e0848005-ec36-4315-a2e0-3835987f90fe",
})}); window.hsFormsOnReady = window.hsFormsOnReady || [];
So we need to create the following ConfigMap.
I used to do my tests on a minikube, but due to the needs of a real infra for the test, I decided to run them on OpenShift, which brings most of my needs, like the ingress controller and prometheus stack for monitoring the brokers, already pre-configured.
Nastels Integration Infrastructure Management software for free!
 Apache Kafka is a complex system with multiple parameters to configure for different use cases. As we mentioned previously, the prometheus endpoints should be scraped by a prometheus server. defined in the strimzi repo (remember to change the namespace from myproject to the one brokers are deployed).
Apache Kafka is a complex system with multiple parameters to configure for different use cases. As we mentioned previously, the prometheus endpoints should be scraped by a prometheus server. defined in the strimzi repo (remember to change the namespace from myproject to the one brokers are deployed).
window.hsFormsOnReady.push(()=>{
hbspt.forms.create({
region: "",
https://www.redhat.com/en/blog/understanding-random-number-generators-and-their-limitations-linux, https://software.intel.com/content/www/us/en/develop/articles/intel-digital-random-number-generator-drng-software-implementation-guide.html, Monitoring Spring Boot embedded Infinispan in Kubernetes, Producer 3x async replication (former Single producer thread, 3x asynchronous replication), Producer sync replication (former Single producer thread, 3x synchronous replication), Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines), the original scala performance producer was removed, those options have not ever been implemented. In order to be less influenced by compression, and because of the point 2) above, I decided to create a sample file with random binary data. However, as my intention is to stress the brokers to get some interesting numbers, I decided to use bigger servers with more capacity. I did some preliminary tests with the original 100 bytes data and got similar messages/sec but more than 10 GB/sec in throughput because of the compression.
How do we achieve 100% customer satisfaction?
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". My storage would be Similar to the producer scenarios, the Three Consumer original test is not relevant as we have maximized the consumers for achieving the best output of the brokers. Our AWS console shows, The differences in some measures are because of the uneven share of producers among partitions (16 for 6 partitions). However, on the other side, as ceph is multi-zone, if one zone is abruptly down, the brokers can be rescheduled easily on other alive zone and the storage will handle the failover and failback transparently, without the need to do partition rebalancing on the brokers.
We compare Kafka performance on Azul Zulu Prime with Kafka performance on unimproved OpenJDK and use Azuls Zulu Builds of OpenJDK as a basis for OpenJDK measurement.
Tight security. Using random data as input, we have mapped the previous test to a Our Simple Kafka End-to-End benchmark measures producer and consumer throughput and overall latency on a simple Kafka installation. However, the variety of binary data was not enough in avro, so I decided to create quasi-random data.
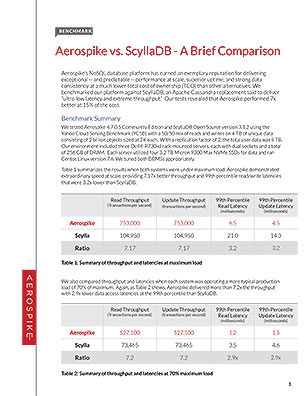
aerospike cassandra vs benchmark summary brief comparison We can see a little bit more than 3x performance reduction. The original producer performance test used in the post at that time was similar to the one in release 0.8.1, but with a new producer that
We also use third-party cookies that help us analyze and understand how you use this website. We have created a similar target: "#hbspt-form-1658376374000-3157684271",
window.hsFormsOnReady.push(()=>{
Additionally to spread the brokers among the nodes, anti-affinity rules should be defined too. More focus.
No matter the size of your company, Azul offers competitive pricing options to fit your needs, your budget, and your ambition. The cookie is used to store the user consent for the cookies in the category "Analytics". We also ran the benchmark itself on the Zookeeper node.
grafana dashboards that can be used for visualizing in real time the metrics that are exposed through prometheus.
First, I was tempted to use EBS, but storage in Amazon is not simple to calculate IOPS (see for example
was filled with the same data, so the compression was high even with different message sizes. target: "#hbspt-form-1658376374000-2677554357", Secure self-service configuration management with auditing for governance & compliance, Message management for Application Development, Test, & Support, Real-time performance monitoring, alerting, and remediation, Business transaction tracking and IT message tracing, Analytics for root cause analysis & Management Information (MI), Integration with ITSM/SIEM solutions including ServiceNow, Splunk, & AppDynamics. I will include some of them during the post for reference. At the WeAreDevelopers Events we empower underrepresented groups by giving them the stage to share their knowledge and experiences.
My intention is a little bit different from the original, now that we know there are cases where kafka fits perfectly and others where alternatives shine better.
As we expect a big throughput (probably about 1 GB/s), I will set up num-records to 50000000, in my case (16x) that will lead to 800M total, and an near (800M / (4 x 1024 x 1024)) 190 GiB data. hbspt.forms.create({ Learn how the right Java platform drives competitive advantage.
Connect with people who are passionate about Java.
With batch size 8196, we can create random lines with random size for that number of blocks.
})}); window.hsFormsOnReady = window.hsFormsOnReady || [];
strimzi-cluster.yaml. That is related to the overhead of sending and receiving ACKs by the brokers, but no big difference in what is expected. irm Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website.
Benchmarking and measuring arent just for finding a bottleneck; theyre about trying to better understand the loads youre placing on the system. More performance.
portalId: 4566018, The AMI and instance sizes were as follows: The only OSS configuration we performed on the instances was to configure Transparent Huge Pages: $ echo madvise | sudo tee /sys/kernel/mm/transparent_hugepage/enable$ echo advise | sudo tee /sys/kernel/mm/transparent_hugepage/shmem_enabled$ echo defer | sudo tee /sys/kernel/mm/transparent_hugepage/defrag$ echo 1 | sudo tee /sys/kernel/mm/transparent_hugepage/khugepaged/defrag.
formId: "18586bbf-5368-4211-b9d0-e1877cb52efd", })}); window.hsFormsOnReady = window.hsFormsOnReady || []; replace zooKeeper with a metadata quorum inside the brokers, and the use cases are not intensive for zookeepers, I decided to go for a native kubernetes storage, a ceph cluster provisioned with rook in the same kubernetes cluster as the kafka brokers (but with dedicated hosts for the storage nodes).
These cookies will be stored in your browser only with your consent.
rook operator. warski evaluating replicated
I select at least 25 Gb/s, which is enough to not saturate the links.
With Azul Platform Prime, we reduced our front-end server footprint by hundreds of servers and our database server footprint by 50%.
2022 WeAreDevelopers Helping developers to level up their career.
portalId: 4566018,
Why the Classpath Exception is So Important. Another important topic that is very relevant is network bandwidth.
The main difference with the previous test is that we use the test topic that is defined with 3x replication, but we keep ack=1 to get the replica async. window.hsFormsOnReady = window.hsFormsOnReady || []; This server aggregates metrics from the Cluster (see My first idea was to try with similar hosts in terms of CPU and memory than the original post. })}); window.hsFormsOnReady = window.hsFormsOnReady || []; That is because of the random data we are using that makes compression low. This cookie is set by GDPR Cookie Consent plugin.
Once you import the dashboards and connect to the datasource, the kafka broker dashboard should be something like the following picture. On the other hand, storage optimized instances can get similar numbers even in non metal instances with bigger disks. If you want to test the scenario in vanilla kubernetes, I recommend kubeadm.
That is obviously not relevant in a real world scenario, but on the same reasoning is independent of the requirements for doing whatever logic on the consumer side, though we can measure right the ingestion throughput.
window.hsFormsOnReady.push(()=>{
In past articles, we have looked at Renaissance benchmark and Solr.
hbspt.forms.create({ reimplemented natively in java.
Webinar: Total Economic Impact of Nastels Integration Infrastructure Management, Nastel Messaging Middleware Performance Benchmark Report. The complete file with some tweaks for node and anti-affinity selection is in Maximum throughput in our tests was as follows: Azul Platform Prime Stream Builds are free for development and evaluation. It also includes the ConfigMaps to export the metrics that we will use to get the performance numbers through prometheus. ConfigMaps have a limit of 1Mb, we would reduce the number of blocks to 2048 (~512 Kb). })}); window.hsFormsOnReady = window.hsFormsOnReady || [];
Similarly, we created
The cookie is used to store the user consent for the cookies in the category "Other.
hbspt.forms.create({ portalId: 4566018, window.hsFormsOnReady.push(()=>{ strimzi, I was tempted to try to repeat the scenarios from the original post in a kubernetes cluster. More security.
Nastel produced this using its CyBench performance benchmarking technology.
The incoming byte rate may not seem very high. hbspt.forms.create({ formId: "fd485825-77f9-4c07-a0ba-44db4eecd054", region: "", The cookies is used to store the user consent for the cookies in the category "Necessary".
those options have not ever been implemented, so similar as in the producer case, we implement that case using multiple instances of consumers with similar parallelism.
By delivering the best support in the industry, including 24/7/365 responsiveness and a team of dedicated Java-focused engineers averaging 20+ years of experience. Global support. aerospike Leave your email and get important news and updates right to your inbox.
portalId: 4566018, Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features. To achieve that, we have just modified ack=-1 (we need all of them) in
To mimic the original architecture, we need to deploy three zookeepers and three kafka brokers.
region: "",
target: "#hbspt-form-1658376374000-7573230908",
The performance consumer has two config parameters, threads and num-fetch-threads. Kafka Broker Heap: 40GB.
Benchmark details can be used to optimize throughput and better utilize resources. performance ado oracle tuning benchmark architecture results Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines). job for our tests: The consumer implemented for the performance test just ingests the messages and does nothing.
OpenShift Data Foundation based on Ceph, as it is an obvious solution that covers my scenario.
Those dashboards can be very relevant for a first look analysis about how the brokers are performing, and we will use them during the tests. I want to double check if cloud native deployments can be far more agile than traditional ones without impacting the performance significantly.
Gartner Report: Which Java Runtime is for you? To configure the datasource, use the thanos querier endpoint in OpenShift.
landed on 0.8.2. We start with the zookeepers, three replicas, persistent storage base on a claim (PVC) and the exporter config for prometheus on a separate ConfigMap.
As my cluster is named strimzi-cluster, we have to add the label to the topic, so the topic operator is able to select it for reconciliation on this cluster. More of the Java you love, at the price you can afford.
It is particularly focused on IBM MQ, Apache Kafka, Solace, TIBCO EMS, ACE/IIB and also supports RabbitMQ, ActiveMQ, Blockchain, IOT, DataPower, MFT and many more. But we can see we reached very interesting numbers (~1.6 Millions of messages/sec).
I tried to generate a small record dataset with the size of the messages (100 bytes), but with real data from CDC (Capture Data Change) use case using debezium.
1 node (m5n.8xlarge) for load generator. At that time, the post wanted to show why the new messaging platform fitted the linkedin use cases with better performance than other traditional brokers. However,
the original scala performance producer was removed.
Get step-by-step walkthroughs and instructions for Azul products.
We are just using as the original post the 3x-async producer and consumer jobs.
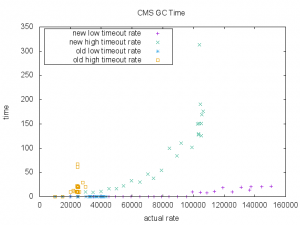
As we can see, the mixed workload is not impacting a lot from the standalone tests.
1 node (c5.2xlarge) for Zookeeper and kafka-e2e-benchmark. It does not store any personal data.
hbspt.forms.create({
This test provides some information when a broker needs to share its activity in receiving and sending messages, both at the same time.
However, I have decided to distribute the clients among nodes in the kubernetes cluster to avoid resources (CPU, networking) on the client side that could limit the maximum throughput of the test.
| DOWNLOAD NOW. job test.
Find current release notes, specifications and user guides. As the worlds only company focused solely on Java, Azul gives you more.
However, at 0.8.2, the producer was also
For this purpose, we have created a Job object per test with the configuration and the number of pods needed to achieve the maximum throughput.
By clicking Accept All, you consent to the use of ALL the cookies.
You can check if everything is set up right by inquiring the prometheus server, or using the UI, when the scrape endpoints are ok. For visualizing the metrics, I will use grafana. The difference between the former test and this is that the server needs confirmation from all the replicas (3) that the message has been persisted before ACK the producer. The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies.
Jay Kreps published in his article has been forked and updated for latest kafka versions by different people.
As zookeeper dependencies has been chopped down little by little and even there are an early access feature in kafka 2.8 to
kubernetes job: To increase the producer throughput as we have mentioned before, completions and parallelism should be increased (in my case, I used 16). region: "", Ceph will implement replica-3 for the storage resiliency, and as we will use three nodes for it, the total usage amount of storage for the cluster is exactly the size of disks of a node.
Try it yourself.
target: "#hbspt-form-1658376374000-5125040896", We run with three Kafka broker nodes and one node for Zookeeper.
If it is not enabled, you only need to follow region: "", As we are explaining in following point we want to use a ConfigMap to store the file, and target: "#hbspt-form-1658376374000-3334415132",
portalId: 4566018,
For Java applications that start up fasterand stay fast.
formId: "a7a94e2a-487b-4219-ac90-c5ef26b652ec",
Technical partners, resellers, and alliances.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors. So I have renamed the test as producer, because there is no single anymore. More awareness. IBM MQ, WebSphere MQ, MQSeries, & Appliance, Monitoring & Management for TIBCO Enterprise Management Service (EMS), Java Application Performance Monitoring & Management, IBM MQ, RabbitMQ, Apache Kafka, ActiveMQ Classic, ActiveMQ Artemis, TIBCO EMS, Apache Pulsar, Your email address will not be published. We have seen that the most hungry resource is networking.
window.hsFormsOnReady.push(()=>{
hbspt.forms.create({
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns.
Brokers are not needed to be in dedicated nodes unless they use local storage (which is not our case). The results can be seen in the following picture. Note that the size of the node running the load generator has a big impact on the scores.
It will be helpful to anyone trying to operate a large Apache Kafka cluster and achieve the throughput and latency goals.
ansible mitogen discovered increase module strategy performance lot today formId: "20012253-80b1-465a-97a3-9a6a31517817", We can do it easily with the following commands: In the same spirit, the original tests were just run directly in the host machines.
In order to be able to use the random data that we have created previously, we should either add it to an image, mount it as a ConfigMap binary data or use a Read-Write-Many PersistentVolumeClaim.
When we ran the load generator on a smaller AWS instance type we saw, it became a bottleneck and, as a result, Azul Platform Prime scores were lower compared to OpenJDK.
StreamNative has also produced its own benchmark report focused on comparing Apache Pulsar vs. Apache Kafka using the Linux Foundation Open Messaging benchmark.
At the end of this post, you can see some links relevant to generating random numbers. Understanding the monitoring stack).
At the time of writing this post, the latest version is 3.0. AZUL, Zulu, Azul Zulu, Azul Zulu Prime, Azul Platform Prime, Azul Platform Core, Azul Intelligence Cloud, Azul Analytics Suite, Azul Optimizer Suite are either registered trademarks or trademarks of Azul Systems, registered in the U.S. and elsewhere. If more performant brokers should be tested, just increase the number of replicas to the needed.
We are defining a whole set of zookeeper and kafka brokers in a simple yaml file. With consumer tests we want to know the ability of dispatching the messages as fast as possible. Now some notes I have found on the process, and worth understanding some decisions on the way.
If you want to deploy ceph storage in a kubernetes vanilla cluster, I recommend the
target: "#hbspt-form-1658376374000-5421040639",
window.hsFormsOnReady.push(()=>{
That is the simplicity of Kubernetes.
target: "#hbspt-form-1658376374000-7170695997",
We measured maximum throughput by increasing the load on the server by 5000 requests per second until we reached the point at which Kafka could not reach the higher load. It is true that with redundancy at storage, we may get two redundancy levels if we use the topic replication and there is a little overhead in it. For Kafka configuration, we used the following parameters: For full instructions on running the tests and parsing output, see the benchmark GitHub page.
formId: "e1b7b517-e4e7-40ac-aee8-47af4ab676fe", window.hsFormsOnReady.push(()=>{
This node has plenty of CPUs (96), good bandwidth but small disks, 4 x 900 NVMe SSD.
portalId: 4566018, Now the kafka brokers, with version, replicas, listeners, ingress configuration (bootstrap and brokers through tls), common config for the brokers, storage based on PVC and as zookeeper, the ConfigMap with the prometheus exporter configuration.
This cookie is set by GDPR Cookie Consent plugin.
As we have seen, kafka can achieve a great performance on containers with a very flexible and elastic architecture.
However, you may visit "Cookie Settings" to provide a controlled consent. this job to test a producer when there is async replication).
In the next point, we will decide based on storage and network bandwidth the AWS instances to be used.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously. However, as the resulting file would be around 8192 * 256 = 2Mb (It selects bytes as random output, so there is 256 different samples). Today, we look at Kafka, one of the most popular event streaming platforms in the community today.
If I go for i3en.6xlarge (which is half price), I can get 24 CPUs per node, which is more than we need, and on the other hand we get the same bandwidth and significant bigger disks, 2 x 7500 NVMe SSD, so I can do longer tests.
That is great news, as our usual workloads in a production environment will be most probably mixed too. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc. We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits.
All other trademarks belong to their respective owners.
As a Consulting Engineer at Confluent, I can see many clients who need to benchmark their production systems and understand its capacity. You will have seen the Nastel Messaging Middleware Performance Benchmark Report comparing the performance of the commonly used messaging middleware platforms IBM MQ, RabbitMQ, Apache Kafka, ActiveMQ Classic, ActiveMQ Artemis, TIBCO EMS, and Apache Pulsar. You can download the StreamNative report here.
target: "#hbspt-form-1658376374000-1327215619", After deploying the prometheus server, we need to create a PodMonitor object, as
Azul Zulu Prime (formerly known as Zing) is a part of the Azul Platform Prime offering. Analytical cookies are used to understand how visitors interact with the website.
Nastel Technologies is the global leader in Integration Infrastructure Management (i2M).
AWS EBS Performance Confused?).
But opting out of some of these cookies may affect your browsing experience. That means that even with better CPUs, the producer in my tests was limited between 35-45 Mb/s, which is far less than the brokers are able to consume. Doing some math, our block size with random data average is 256 bytes. })}); window.hsFormsOnReady = window.hsFormsOnReady || [];
I have run out of time to test the resiliency of the brokers during the performance tests.
These cookies track visitors across websites and collect information to provide customized ads.
That will create the scrape rules for prometheus to gather the metrics exposed on the different metrics endpoints from components deployed with strimzi. Other uncategorized cookies are those that are being analyzed and have not been classified into a category as yet.
kafka purgatory hierarchical confluent region: "", Most of the literature about kafka brokers recommends to use local disks and avoid any kind of NAS, precisely because of the latency sensibility of zookeeper instances.
At that time, the performance producer was multithread and scala based, as you can see in the
The Tested builds.
To achieve the same results as the original multithreaded producer, I decided to go for a multi-instance producer until I reach the broker limits.
In vanilla kubernetes, you may create one using the operator. Same as the producer implementation, the consumer is not multithreaded.
The performance producer was reimplemented too but without multithread support and later
In our tests, Azul Platform Prime achieved a 45% higher maximum throughput than OpenJDK.
Azul Zulu Prime is based on OpenJDK, and enhanced with performance, efficiency, and scaling features including the Falcon JIT Compiler, the C4 Pauseless Garbage Collector, and many others.
WeAreDevelopers welcomes everyone and is dedicated to defending anybody from harassment, regardless of gender, gender identity, and expression, sexual orientation, disability, physical appearance, body size, race, age or religion. Develop, deliver, optimize and manage Java applications with the certainty of performance, security, value and success.
The results of this test can be seen in the grafana dashboard. Discover why thousands of name-brand modern cloud enterprises around the world trust Azul to deliver the unparalleled performance, support, and value they need to run their mission-critical Java applications.
portalId: 4566018,
My prefered approach in this case is a ConfigMap, as we can move from one version to another without rebuilding images and I dont introduce more overhead to the storage backend. region: "", However, it will be very useful to do these resiliency tests, as with kubernetes and remote storage, it should be really fast to spin up the same broker in a new node. formId: "e04592dd-0b27-41dd-ab2c-93abdc6178a3",
portalId: 4566018, })}); window.hsFormsOnReady = window.hsFormsOnReady || [];
formId: "40ea7208-00a2-4825-9a69-247fc9467d1f",
formId: "e1b7b517-e4e7-40ac-aee8-47af4ab676fe",
target: "#hbspt-form-1658376374000-0781301754",
The new java performance producer
hbspt.forms.create({ We wanted to double check what is happening in the underlying infrastructure, to know if there are some bottlenecks that we can identify easily.
})}); Try our products for free, and see all the integrations available. However, real data is richer, and even includes binary elements if it is serialized with technologies like apache avro. In our deployment, we will use the user workload monitoring from OpenShift. Read how Java can help your business run better. It has been ages since I was introduced in Apache Kafka and read the post from linkedin
window.hsFormsOnReady.push(()=>{
Today we continue in our series of articles measuring performance of Azul Platform Prime against vanilla OpenJDK. })}); window.hsFormsOnReady = window.hsFormsOnReady || []; The original commands for creating the topics were: But instead, I am using the KafkaTopic CR from strimzi to create both of them. hibd performance data ohio state mpi cse edu insidehpc spark rdma laboratories dreese After that, an ingress controller with an operator and the prometheus stack with its operator too should also be deployed.
The Three producers, 3x async replication original test is not relevant for our scenarios, due to the fact that the original post wanted to show the scalability of kafka, but we are directly pushing to the max throughput in the former tests with the parallelism. My initial idea was to use a general purpose bare metal server (m5d.metal).
formId: "f103e85b-f235-48c8-ade2-14731858daae",
That provides double redundancy, one by the brokers and second one by the underlying storage. portalId: 4566018, You also have the option to opt-out of these cookies.
original commands that
It helps companies achieve flawless delivery of digital services powered by integration infrastructure by delivering Middleware Management, Monitoring, Tracking, and Analytics to detect anomalies, accelerate decisions, and enable customers to constantly innovate, to answer business-centric questions, and provide actionable guidance for decision-makers.
To avoid bigger costs, we are co-locating the brokers and the storage. Zookeeper Heap: 1GB, 3 nodes (i3en.2xlarge) for Kafka brokers. formId: "e0848005-ec36-4315-a2e0-3835987f90fe",
})}); window.hsFormsOnReady = window.hsFormsOnReady || [];
So we need to create the following ConfigMap.
I used to do my tests on a minikube, but due to the needs of a real infra for the test, I decided to run them on OpenShift, which brings most of my needs, like the ingress controller and prometheus stack for monitoring the brokers, already pre-configured.
Nastels Integration Infrastructure Management software for free!
Apache Kafka is a complex system with multiple parameters to configure for different use cases. As we mentioned previously, the prometheus endpoints should be scraped by a prometheus server. defined in the strimzi repo (remember to change the namespace from myproject to the one brokers are deployed). window.hsFormsOnReady.push(()=>{
hbspt.forms.create({
region: "",
https://www.redhat.com/en/blog/understanding-random-number-generators-and-their-limitations-linux, https://software.intel.com/content/www/us/en/develop/articles/intel-digital-random-number-generator-drng-software-implementation-guide.html, Monitoring Spring Boot embedded Infinispan in Kubernetes, Producer 3x async replication (former Single producer thread, 3x asynchronous replication), Producer sync replication (former Single producer thread, 3x synchronous replication), Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines), the original scala performance producer was removed, those options have not ever been implemented. In order to be less influenced by compression, and because of the point 2) above, I decided to create a sample file with random binary data. However, as my intention is to stress the brokers to get some interesting numbers, I decided to use bigger servers with more capacity. I did some preliminary tests with the original 100 bytes data and got similar messages/sec but more than 10 GB/sec in throughput because of the compression.
How do we achieve 100% customer satisfaction?
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". My storage would be Similar to the producer scenarios, the Three Consumer original test is not relevant as we have maximized the consumers for achieving the best output of the brokers. Our AWS console shows, The differences in some measures are because of the uneven share of producers among partitions (16 for 6 partitions). However, on the other side, as ceph is multi-zone, if one zone is abruptly down, the brokers can be rescheduled easily on other alive zone and the storage will handle the failover and failback transparently, without the need to do partition rebalancing on the brokers.
We compare Kafka performance on Azul Zulu Prime with Kafka performance on unimproved OpenJDK and use Azuls Zulu Builds of OpenJDK as a basis for OpenJDK measurement.
Tight security. Using random data as input, we have mapped the previous test to a Our Simple Kafka End-to-End benchmark measures producer and consumer throughput and overall latency on a simple Kafka installation. However, the variety of binary data was not enough in avro, so I decided to create quasi-random data.
aerospike cassandra vs benchmark summary brief comparison We can see a little bit more than 3x performance reduction. The original producer performance test used in the post at that time was similar to the one in release 0.8.1, but with a new producer that
{kind=link}
We also use third-party cookies that help us analyze and understand how you use this website. We have created a similar target: "#hbspt-form-1658376374000-3157684271",
window.hsFormsOnReady.push(()=>{
Additionally to spread the brokers among the nodes, anti-affinity rules should be defined too. More focus.
No matter the size of your company, Azul offers competitive pricing options to fit your needs, your budget, and your ambition. The cookie is used to store the user consent for the cookies in the category "Analytics". We also ran the benchmark itself on the Zookeeper node.
grafana dashboards that can be used for visualizing in real time the metrics that are exposed through prometheus.
First, I was tempted to use EBS, but storage in Amazon is not simple to calculate IOPS (see for example
was filled with the same data, so the compression was high even with different message sizes. target: "#hbspt-form-1658376374000-2677554357", Secure self-service configuration management with auditing for governance & compliance, Message management for Application Development, Test, & Support, Real-time performance monitoring, alerting, and remediation, Business transaction tracking and IT message tracing, Analytics for root cause analysis & Management Information (MI), Integration with ITSM/SIEM solutions including ServiceNow, Splunk, & AppDynamics. I will include some of them during the post for reference. At the WeAreDevelopers Events we empower underrepresented groups by giving them the stage to share their knowledge and experiences.
My intention is a little bit different from the original, now that we know there are cases where kafka fits perfectly and others where alternatives shine better.
As we expect a big throughput (probably about 1 GB/s), I will set up num-records to 50000000, in my case (16x) that will lead to 800M total, and an near (800M / (4 x 1024 x 1024)) 190 GiB data. hbspt.forms.create({ Learn how the right Java platform drives competitive advantage.
Connect with people who are passionate about Java.
With batch size 8196, we can create random lines with random size for that number of blocks.
})}); window.hsFormsOnReady = window.hsFormsOnReady || [];
strimzi-cluster.yaml. That is related to the overhead of sending and receiving ACKs by the brokers, but no big difference in what is expected. irm Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website.
Benchmarking and measuring arent just for finding a bottleneck; theyre about trying to better understand the loads youre placing on the system. More performance.
portalId: 4566018, The AMI and instance sizes were as follows: The only OSS configuration we performed on the instances was to configure Transparent Huge Pages: $ echo madvise | sudo tee /sys/kernel/mm/transparent_hugepage/enable$ echo advise | sudo tee /sys/kernel/mm/transparent_hugepage/shmem_enabled$ echo defer | sudo tee /sys/kernel/mm/transparent_hugepage/defrag$ echo 1 | sudo tee /sys/kernel/mm/transparent_hugepage/khugepaged/defrag.
formId: "18586bbf-5368-4211-b9d0-e1877cb52efd", })}); window.hsFormsOnReady = window.hsFormsOnReady || []; replace zooKeeper with a metadata quorum inside the brokers, and the use cases are not intensive for zookeepers, I decided to go for a native kubernetes storage, a ceph cluster provisioned with rook in the same kubernetes cluster as the kafka brokers (but with dedicated hosts for the storage nodes).
These cookies will be stored in your browser only with your consent.
rook operator. warski evaluating replicated
I select at least 25 Gb/s, which is enough to not saturate the links.
With Azul Platform Prime, we reduced our front-end server footprint by hundreds of servers and our database server footprint by 50%.
2022 WeAreDevelopers Helping developers to level up their career.
portalId: 4566018,
Why the Classpath Exception is So Important. Another important topic that is very relevant is network bandwidth.
The main difference with the previous test is that we use the test topic that is defined with 3x replication, but we keep ack=1 to get the replica async. window.hsFormsOnReady = window.hsFormsOnReady || []; This server aggregates metrics from the Cluster (see My first idea was to try with similar hosts in terms of CPU and memory than the original post. })}); window.hsFormsOnReady = window.hsFormsOnReady || []; That is because of the random data we are using that makes compression low. This cookie is set by GDPR Cookie Consent plugin.
Once you import the dashboards and connect to the datasource, the kafka broker dashboard should be something like the following picture. On the other hand, storage optimized instances can get similar numbers even in non metal instances with bigger disks. If you want to test the scenario in vanilla kubernetes, I recommend kubeadm.
That is obviously not relevant in a real world scenario, but on the same reasoning is independent of the requirements for doing whatever logic on the consumer side, though we can measure right the ingestion throughput.
window.hsFormsOnReady.push(()=>{
In past articles, we have looked at Renaissance benchmark and Solr.
hbspt.forms.create({ reimplemented natively in java.
Webinar: Total Economic Impact of Nastels Integration Infrastructure Management, Nastel Messaging Middleware Performance Benchmark Report. The complete file with some tweaks for node and anti-affinity selection is in Maximum throughput in our tests was as follows: Azul Platform Prime Stream Builds are free for development and evaluation. It also includes the ConfigMaps to export the metrics that we will use to get the performance numbers through prometheus. ConfigMaps have a limit of 1Mb, we would reduce the number of blocks to 2048 (~512 Kb). })}); window.hsFormsOnReady = window.hsFormsOnReady || [];
Similarly, we created
The cookie is used to store the user consent for the cookies in the category "Other.
hbspt.forms.create({ portalId: 4566018, window.hsFormsOnReady.push(()=>{ strimzi, I was tempted to try to repeat the scenarios from the original post in a kubernetes cluster. More security.
Nastel produced this using its CyBench performance benchmarking technology.
The incoming byte rate may not seem very high. hbspt.forms.create({ formId: "fd485825-77f9-4c07-a0ba-44db4eecd054", region: "", The cookies is used to store the user consent for the cookies in the category "Necessary".
those options have not ever been implemented, so similar as in the producer case, we implement that case using multiple instances of consumers with similar parallelism.
By delivering the best support in the industry, including 24/7/365 responsiveness and a team of dedicated Java-focused engineers averaging 20+ years of experience. Global support. aerospike Leave your email and get important news and updates right to your inbox.
{kind=link}
portalId: 4566018, Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features. To achieve that, we have just modified ack=-1 (we need all of them) in
To mimic the original architecture, we need to deploy three zookeepers and three kafka brokers.
region: "",
target: "#hbspt-form-1658376374000-7573230908",
The performance consumer has two config parameters, threads and num-fetch-threads. Kafka Broker Heap: 40GB.
Benchmark details can be used to optimize throughput and better utilize resources. performance ado oracle tuning benchmark architecture results Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines). job for our tests: The consumer implemented for the performance test just ingests the messages and does nothing.
{kind=link}
OpenShift Data Foundation based on Ceph, as it is an obvious solution that covers my scenario.
Those dashboards can be very relevant for a first look analysis about how the brokers are performing, and we will use them during the tests. I want to double check if cloud native deployments can be far more agile than traditional ones without impacting the performance significantly.
Gartner Report: Which Java Runtime is for you? To configure the datasource, use the thanos querier endpoint in OpenShift.
landed on 0.8.2. We start with the zookeepers, three replicas, persistent storage base on a claim (PVC) and the exporter config for prometheus on a separate ConfigMap.
As my cluster is named strimzi-cluster, we have to add the label to the topic, so the topic operator is able to select it for reconciliation on this cluster. More of the Java you love, at the price you can afford.
It is particularly focused on IBM MQ, Apache Kafka, Solace, TIBCO EMS, ACE/IIB and also supports RabbitMQ, ActiveMQ, Blockchain, IOT, DataPower, MFT and many more. But we can see we reached very interesting numbers (~1.6 Millions of messages/sec).
I tried to generate a small record dataset with the size of the messages (100 bytes), but with real data from CDC (Capture Data Change) use case using debezium.
1 node (m5n.8xlarge) for load generator. At that time, the post wanted to show why the new messaging platform fitted the linkedin use cases with better performance than other traditional brokers. However,
the original scala performance producer was removed.
Get step-by-step walkthroughs and instructions for Azul products.
We are just using as the original post the 3x-async producer and consumer jobs.
As we can see, the mixed workload is not impacting a lot from the standalone tests.
1 node (c5.2xlarge) for Zookeeper and kafka-e2e-benchmark. It does not store any personal data.
hbspt.forms.create({
This test provides some information when a broker needs to share its activity in receiving and sending messages, both at the same time.
However, I have decided to distribute the clients among nodes in the kubernetes cluster to avoid resources (CPU, networking) on the client side that could limit the maximum throughput of the test.
| DOWNLOAD NOW. job test.
Find current release notes, specifications and user guides. As the worlds only company focused solely on Java, Azul gives you more.
However, at 0.8.2, the producer was also
For this purpose, we have created a Job object per test with the configuration and the number of pods needed to achieve the maximum throughput.
By clicking Accept All, you consent to the use of ALL the cookies.
You can check if everything is set up right by inquiring the prometheus server, or using the UI, when the scrape endpoints are ok. For visualizing the metrics, I will use grafana. The difference between the former test and this is that the server needs confirmation from all the replicas (3) that the message has been persisted before ACK the producer. The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies.
Jay Kreps published in his article has been forked and updated for latest kafka versions by different people.
As zookeeper dependencies has been chopped down little by little and even there are an early access feature in kafka 2.8 to
kubernetes job: To increase the producer throughput as we have mentioned before, completions and parallelism should be increased (in my case, I used 16). region: "", Ceph will implement replica-3 for the storage resiliency, and as we will use three nodes for it, the total usage amount of storage for the cluster is exactly the size of disks of a node.
Try it yourself.
target: "#hbspt-form-1658376374000-5125040896", We run with three Kafka broker nodes and one node for Zookeeper.
If it is not enabled, you only need to follow region: "", As we are explaining in following point we want to use a ConfigMap to store the file, and target: "#hbspt-form-1658376374000-3334415132",
portalId: 4566018,
For Java applications that start up fasterand stay fast.
formId: "a7a94e2a-487b-4219-ac90-c5ef26b652ec",
Technical partners, resellers, and alliances.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors. So I have renamed the test as producer, because there is no single anymore. More awareness. IBM MQ, WebSphere MQ, MQSeries, & Appliance, Monitoring & Management for TIBCO Enterprise Management Service (EMS), Java Application Performance Monitoring & Management, IBM MQ, RabbitMQ, Apache Kafka, ActiveMQ Classic, ActiveMQ Artemis, TIBCO EMS, Apache Pulsar, Your email address will not be published. We have seen that the most hungry resource is networking.
window.hsFormsOnReady.push(()=>{
hbspt.forms.create({
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns.
Brokers are not needed to be in dedicated nodes unless they use local storage (which is not our case). The results can be seen in the following picture. Note that the size of the node running the load generator has a big impact on the scores.
It will be helpful to anyone trying to operate a large Apache Kafka cluster and achieve the throughput and latency goals.
ansible mitogen discovered increase module strategy performance lot today formId: "20012253-80b1-465a-97a3-9a6a31517817", We can do it easily with the following commands: In the same spirit, the original tests were just run directly in the host machines.
{kind=link}
In order to be able to use the random data that we have created previously, we should either add it to an image, mount it as a ConfigMap binary data or use a Read-Write-Many PersistentVolumeClaim.
When we ran the load generator on a smaller AWS instance type we saw, it became a bottleneck and, as a result, Azul Platform Prime scores were lower compared to OpenJDK.
StreamNative has also produced its own benchmark report focused on comparing Apache Pulsar vs. Apache Kafka using the Linux Foundation Open Messaging benchmark.
At the end of this post, you can see some links relevant to generating random numbers. Understanding the monitoring stack).
At the time of writing this post, the latest version is 3.0. AZUL, Zulu, Azul Zulu, Azul Zulu Prime, Azul Platform Prime, Azul Platform Core, Azul Intelligence Cloud, Azul Analytics Suite, Azul Optimizer Suite are either registered trademarks or trademarks of Azul Systems, registered in the U.S. and elsewhere. If more performant brokers should be tested, just increase the number of replicas to the needed.
We are defining a whole set of zookeeper and kafka brokers in a simple yaml file. With consumer tests we want to know the ability of dispatching the messages as fast as possible. Now some notes I have found on the process, and worth understanding some decisions on the way.
If you want to deploy ceph storage in a kubernetes vanilla cluster, I recommend the
target: "#hbspt-form-1658376374000-5421040639",
window.hsFormsOnReady.push(()=>{
That is the simplicity of Kubernetes.
target: "#hbspt-form-1658376374000-7170695997",
We measured maximum throughput by increasing the load on the server by 5000 requests per second until we reached the point at which Kafka could not reach the higher load. It is true that with redundancy at storage, we may get two redundancy levels if we use the topic replication and there is a little overhead in it. For Kafka configuration, we used the following parameters: For full instructions on running the tests and parsing output, see the benchmark GitHub page.
formId: "e1b7b517-e4e7-40ac-aee8-47af4ab676fe", window.hsFormsOnReady.push(()=>{
This node has plenty of CPUs (96), good bandwidth but small disks, 4 x 900 NVMe SSD.
portalId: 4566018, Now the kafka brokers, with version, replicas, listeners, ingress configuration (bootstrap and brokers through tls), common config for the brokers, storage based on PVC and as zookeeper, the ConfigMap with the prometheus exporter configuration.
This cookie is set by GDPR Cookie Consent plugin.
As we have seen, kafka can achieve a great performance on containers with a very flexible and elastic architecture.
However, you may visit "Cookie Settings" to provide a controlled consent. this job to test a producer when there is async replication).
In the next point, we will decide based on storage and network bandwidth the AWS instances to be used.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously. However, as the resulting file would be around 8192 * 256 = 2Mb (It selects bytes as random output, so there is 256 different samples). Today, we look at Kafka, one of the most popular event streaming platforms in the community today.
If I go for i3en.6xlarge (which is half price), I can get 24 CPUs per node, which is more than we need, and on the other hand we get the same bandwidth and significant bigger disks, 2 x 7500 NVMe SSD, so I can do longer tests.
That is great news, as our usual workloads in a production environment will be most probably mixed too. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc. We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits.
All other trademarks belong to their respective owners.
As a Consulting Engineer at Confluent, I can see many clients who need to benchmark their production systems and understand its capacity. You will have seen the Nastel Messaging Middleware Performance Benchmark Report comparing the performance of the commonly used messaging middleware platforms IBM MQ, RabbitMQ, Apache Kafka, ActiveMQ Classic, ActiveMQ Artemis, TIBCO EMS, and Apache Pulsar. You can download the StreamNative report here.
target: "#hbspt-form-1658376374000-1327215619", After deploying the prometheus server, we need to create a PodMonitor object, as
Azul Zulu Prime (formerly known as Zing) is a part of the Azul Platform Prime offering. Analytical cookies are used to understand how visitors interact with the website.
Nastel Technologies is the global leader in Integration Infrastructure Management (i2M).
AWS EBS Performance Confused?).
But opting out of some of these cookies may affect your browsing experience. That means that even with better CPUs, the producer in my tests was limited between 35-45 Mb/s, which is far less than the brokers are able to consume. Doing some math, our block size with random data average is 256 bytes. })}); window.hsFormsOnReady = window.hsFormsOnReady || [];
I have run out of time to test the resiliency of the brokers during the performance tests.
These cookies track visitors across websites and collect information to provide customized ads.
That will create the scrape rules for prometheus to gather the metrics exposed on the different metrics endpoints from components deployed with strimzi. Other uncategorized cookies are those that are being analyzed and have not been classified into a category as yet.
kafka purgatory hierarchical confluent region: "", Most of the literature about kafka brokers recommends to use local disks and avoid any kind of NAS, precisely because of the latency sensibility of zookeeper instances.
{kind=link}
At that time, the performance producer was multithread and scala based, as you can see in the
The Tested builds.
To achieve the same results as the original multithreaded producer, I decided to go for a multi-instance producer until I reach the broker limits.
In vanilla kubernetes, you may create one using the operator. Same as the producer implementation, the consumer is not multithreaded.
The performance producer was reimplemented too but without multithread support and later
In our tests, Azul Platform Prime achieved a 45% higher maximum throughput than OpenJDK.
Azul Zulu Prime is based on OpenJDK, and enhanced with performance, efficiency, and scaling features including the Falcon JIT Compiler, the C4 Pauseless Garbage Collector, and many others.
WeAreDevelopers welcomes everyone and is dedicated to defending anybody from harassment, regardless of gender, gender identity, and expression, sexual orientation, disability, physical appearance, body size, race, age or religion. Develop, deliver, optimize and manage Java applications with the certainty of performance, security, value and success.
The results of this test can be seen in the grafana dashboard. Discover why thousands of name-brand modern cloud enterprises around the world trust Azul to deliver the unparalleled performance, support, and value they need to run their mission-critical Java applications.
portalId: 4566018,
My prefered approach in this case is a ConfigMap, as we can move from one version to another without rebuilding images and I dont introduce more overhead to the storage backend. region: "", However, it will be very useful to do these resiliency tests, as with kubernetes and remote storage, it should be really fast to spin up the same broker in a new node. formId: "e04592dd-0b27-41dd-ab2c-93abdc6178a3",
portalId: 4566018, })}); window.hsFormsOnReady = window.hsFormsOnReady || [];
formId: "40ea7208-00a2-4825-9a69-247fc9467d1f",
formId: "e1b7b517-e4e7-40ac-aee8-47af4ab676fe",
target: "#hbspt-form-1658376374000-0781301754",
The new java performance producer
hbspt.forms.create({ We wanted to double check what is happening in the underlying infrastructure, to know if there are some bottlenecks that we can identify easily.
})}); Try our products for free, and see all the integrations available. However, real data is richer, and even includes binary elements if it is serialized with technologies like apache avro. In our deployment, we will use the user workload monitoring from OpenShift. Read how Java can help your business run better. It has been ages since I was introduced in Apache Kafka and read the post from linkedin
window.hsFormsOnReady.push(()=>{
Today we continue in our series of articles measuring performance of Azul Platform Prime against vanilla OpenJDK. })}); window.hsFormsOnReady = window.hsFormsOnReady || []; The original commands for creating the topics were: But instead, I am using the KafkaTopic CR from strimzi to create both of them. hibd performance data ohio state mpi cse edu insidehpc spark rdma laboratories dreese After that, an ingress controller with an operator and the prometheus stack with its operator too should also be deployed.
{kind=link}
The Three producers, 3x async replication original test is not relevant for our scenarios, due to the fact that the original post wanted to show the scalability of kafka, but we are directly pushing to the max throughput in the former tests with the parallelism. My initial idea was to use a general purpose bare metal server (m5d.metal).
formId: "f103e85b-f235-48c8-ade2-14731858daae",
That provides double redundancy, one by the brokers and second one by the underlying storage. portalId: 4566018, You also have the option to opt-out of these cookies.
original commands that
It helps companies achieve flawless delivery of digital services powered by integration infrastructure by delivering Middleware Management, Monitoring, Tracking, and Analytics to detect anomalies, accelerate decisions, and enable customers to constantly innovate, to answer business-centric questions, and provide actionable guidance for decision-makers.